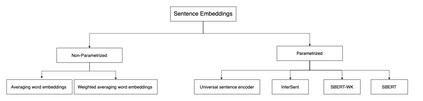
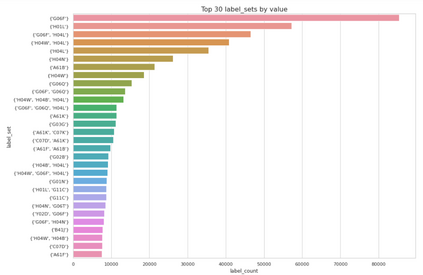
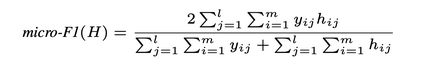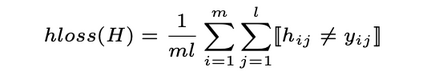Patent data is an important source of knowledge for innovation research. While the technological similarity between pairs of patents is a key enabling indicator for patent analysis. Recently researchers have been using patent vector space models based on different NLP embeddings models to calculate technological similarity between pairs of patents to help better understand innovations, patent landscaping, technology mapping, and patent quality evaluation. To the best of our knowledge, there is not a comprehensive survey that builds a big picture of embedding models' performance for calculating patent similarity indicators. Therefore, in this study, we provide an overview of the accuracy of these algorithms based on patent classification performance. In a detailed discussion, we report the performance of the top 3 algorithms at section, class, and subclass levels. The results based on the first claim of patents show that PatentSBERTa, Bert-for-patents, and TF-IDF Weighted Word Embeddings have the best accuracy for computing sentence embeddings at the subclass level. According to the first results, the performance of the models in different classes varies which shows researchers in patent analysis can utilize the results of this study for choosing the best proper model based on the specific section of patent data they used.
翻译:专利数据是创新研究知识的一个重要来源。虽然专利对等技术相似性是专利分析的主要有利指标。最近研究人员一直在使用基于不同NLP嵌入模型的专利矢量空间模型,以计算专利对等技术相似性,以帮助更好地了解创新、专利景观美化、技术绘图和专利质量评估。就我们所知的最好情况而言,目前没有一项全面调查,为计算专利相似性指标而构建嵌入模型业绩的大图。因此,在本研究中,我们提供了基于专利分类绩效的这些算法的准确性概览。在一次详细讨论中,我们报告了科、班和次级一级前3种算法的性能。根据专利主张提出的第一项结果显示,P专利SBERTa、Bert-for-patents和TF-IDF Weight-Wewighted Webeddings在子级嵌入计算机判决方面最准确性能。根据初步结果,不同类别的模型的性能显示,在专利分析中研究人员能够利用这项研究的结果,根据具体数据选择最佳的模型。