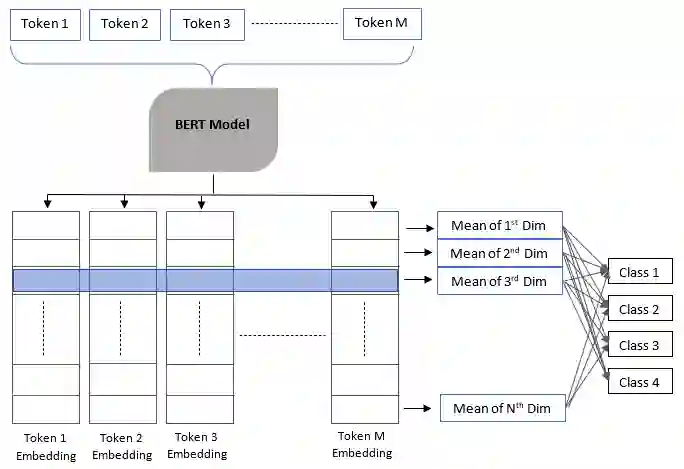
Inherently, the legal domain contains a vast amount of data in text format. Therefore it requires the application of Natural Language Processing (NLP) to cater to the analytically demanding needs of the domain. The advancement of NLP is spreading through various domains, such as the legal domain, in forms of practical applications and academic research. Identifying critical sentences, facts and arguments in a legal case is a tedious task for legal professionals. In this research we explore the usage of sentence embeddings for multi-class classification to identify critical sentences in a legal case, in the perspective of the main parties present in the case. In addition, a task-specific loss function is defined in order to improve the accuracy restricted by the straightforward use of categorical cross entropy loss.
翻译:法律领域必然包含大量文本格式的数据,因此,它需要应用《自然语言处理法》来满足该领域在分析上要求很高的需要; 国家语言处理法的进展正在以实际应用和学术研究的形式通过各个领域,例如法律领域,以实际应用和学术研究的形式扩散; 确定法律案件的关键判决、事实和论点是法律专业人员的一项陈腐的任务; 在这项研究中,我们探讨如何使用包含多级分类的句子,以便从案件所涉主要当事方的角度确定法律案件中的关键判决; 此外,界定了具体任务的损失职能,以提高因直接使用绝对跨胎损失而限制的准确性。