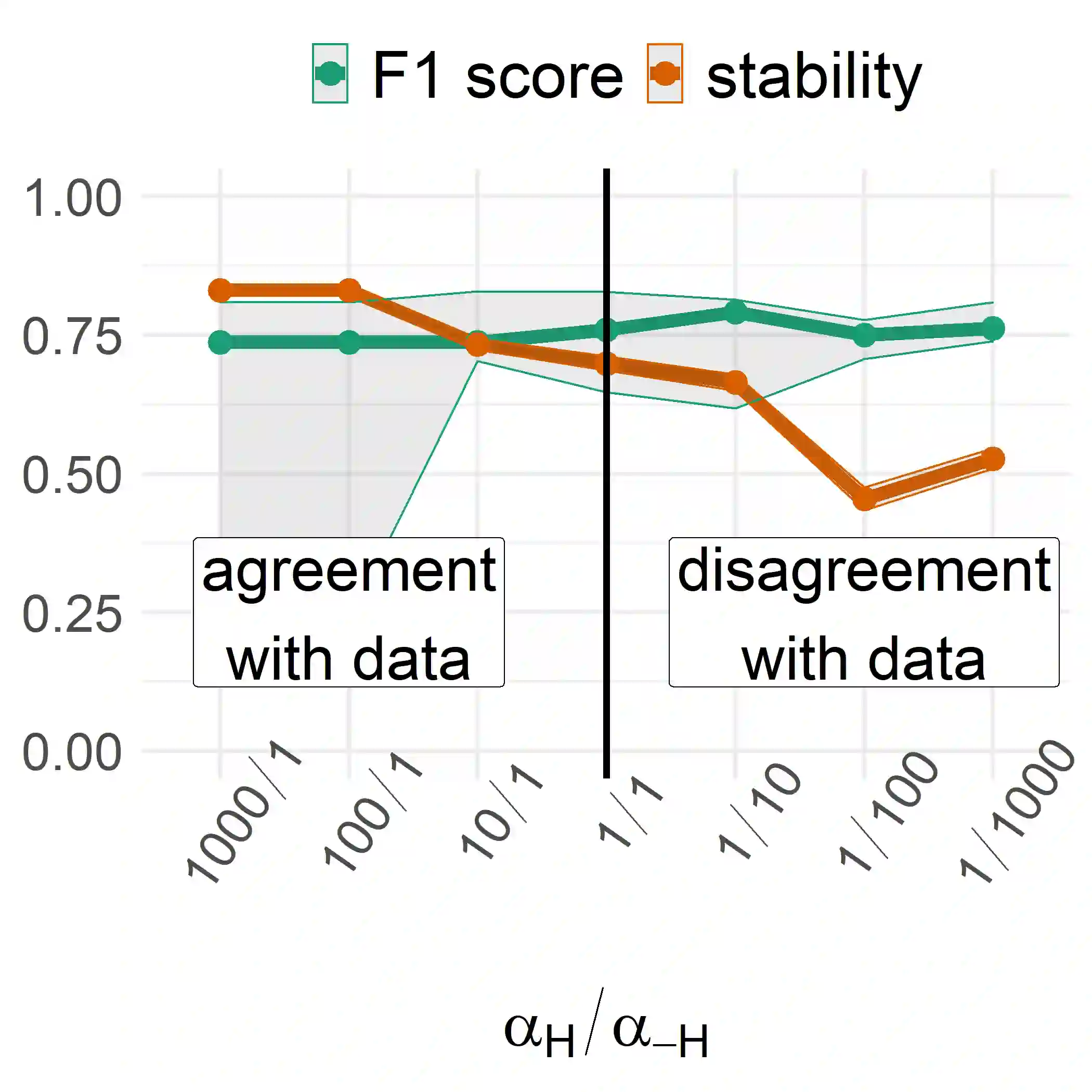
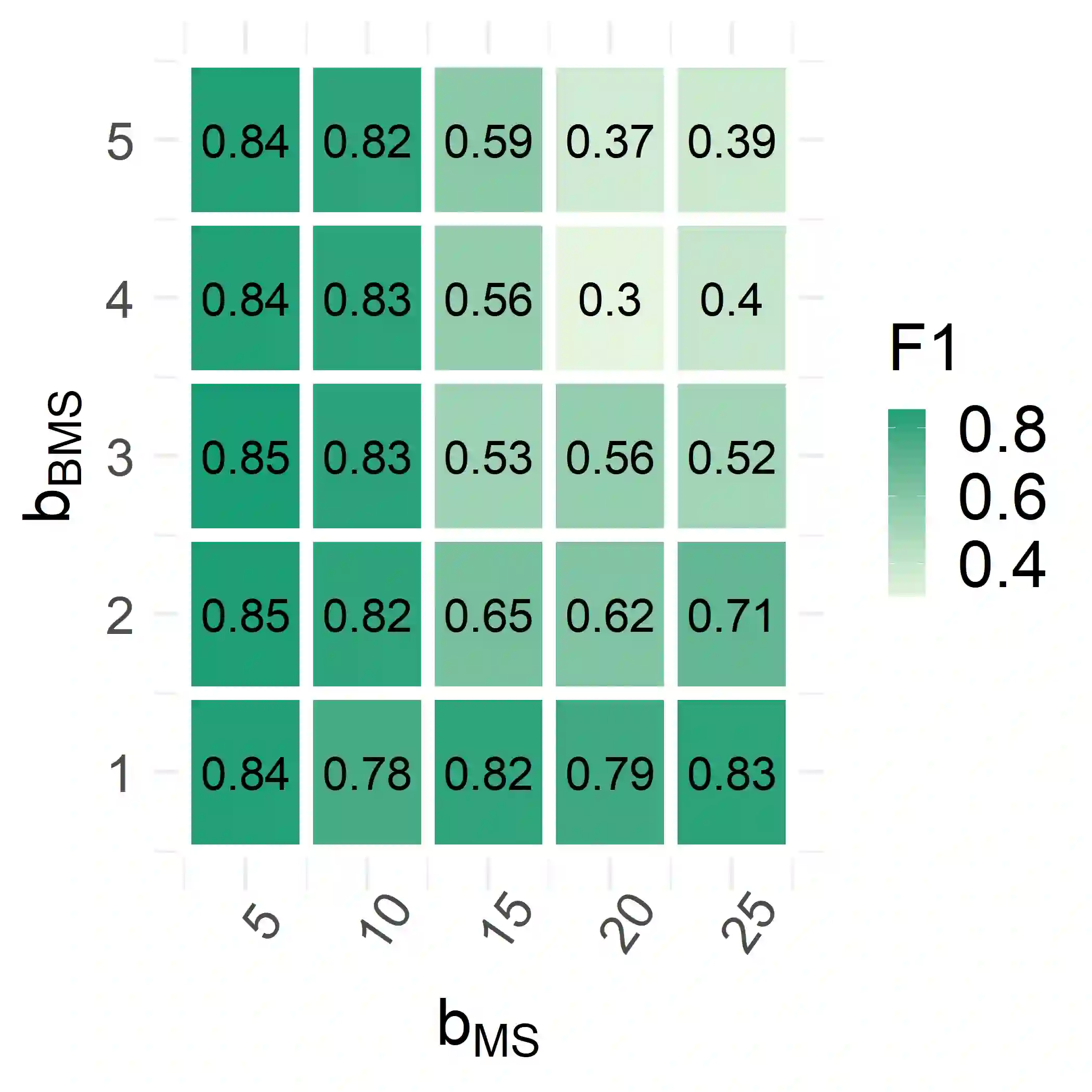
Training machine learning models on high-dimensional datasets is a challenging task and requires measures to prevent overfitting and to keep model complexity low. Feature selection, which represents such a measure, plays a key role in data preprocessing and may provide insights into the systematic variation in the data. The latter aspect is crucial in domains that rely on model interpretability, such as life sciences. We propose UBayFS, an ensemble feature selection technique, embedded in a Bayesian statistical framework. Our approach considers two sources of information: data and domain knowledge. We build an ensemble of elementary feature selectors that extract information from empirical data and aggregate this information to form a meta-model, which compensates for inconsistencies between elementary feature selectors. The user guides UBayFS by weighting features and penalizing specific feature blocks or combinations. The framework builds on a multinomial likelihood and a novel version of constrained Dirichlet-type prior distribution, involving initial feature weights and side constraints. In a quantitative evaluation, we demonstrate that the presented framework allows for a balanced trade-off between user knowledge and data observations. A comparison with standard feature selectors underlines that UBayFS achieves competitive performance, while providing additional flexibility to incorporate domain knowledge.
翻译:高维数据集的机器培训学习模型是一项艰巨的任务,需要采取措施防止过度配置和保持模型复杂性低。特征选择代表了这样一种措施,在数据预处理中发挥着关键作用,并可能对数据的系统变异提供洞察力。在依赖模型可解释性的领域,如生命科学,后一个方面至关重要。我们建议采用混合特征选择技术UBayFS,这是包含在巴伊西亚统计框架中的一种混合特征选择技术。我们的方法考虑到两个信息来源:数据和域知识。我们建立了一套基本特征选择器,从经验数据中提取信息并汇总这些信息,形成一个元模型,以弥补基本特征选择器之间的不一致。用户指南UBayFS通过加权特征和惩罚特定特征块或组合来弥补这些特征的不一致。框架基于多种可能性和新版本的限制性Drichlet型的先前分布,包括初始特征权重和侧项限制。在定量评估中,我们证明所提出的框架允许用户知识与数据观测之间的平衡交易。与标准特征选择器之间的比较,同时强调标准特征选择器的竞争力,同时强调实现额外的业绩。