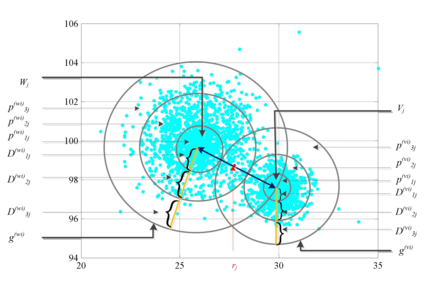
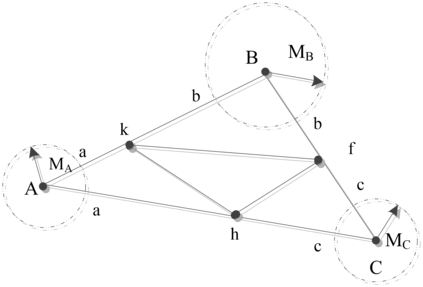
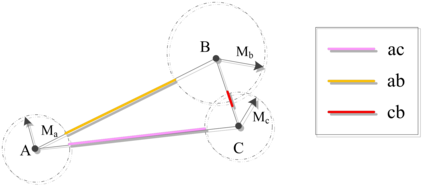
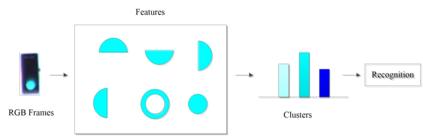
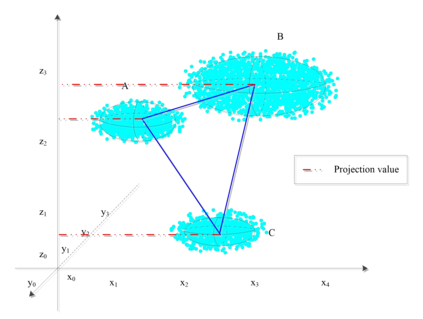
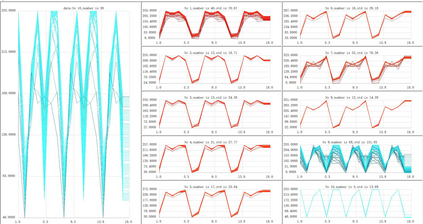
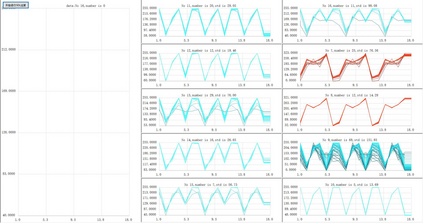
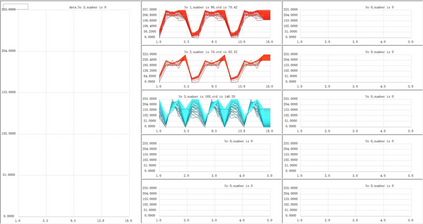
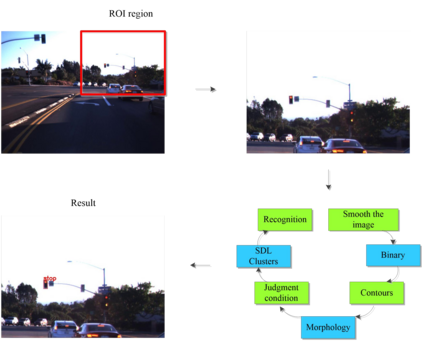
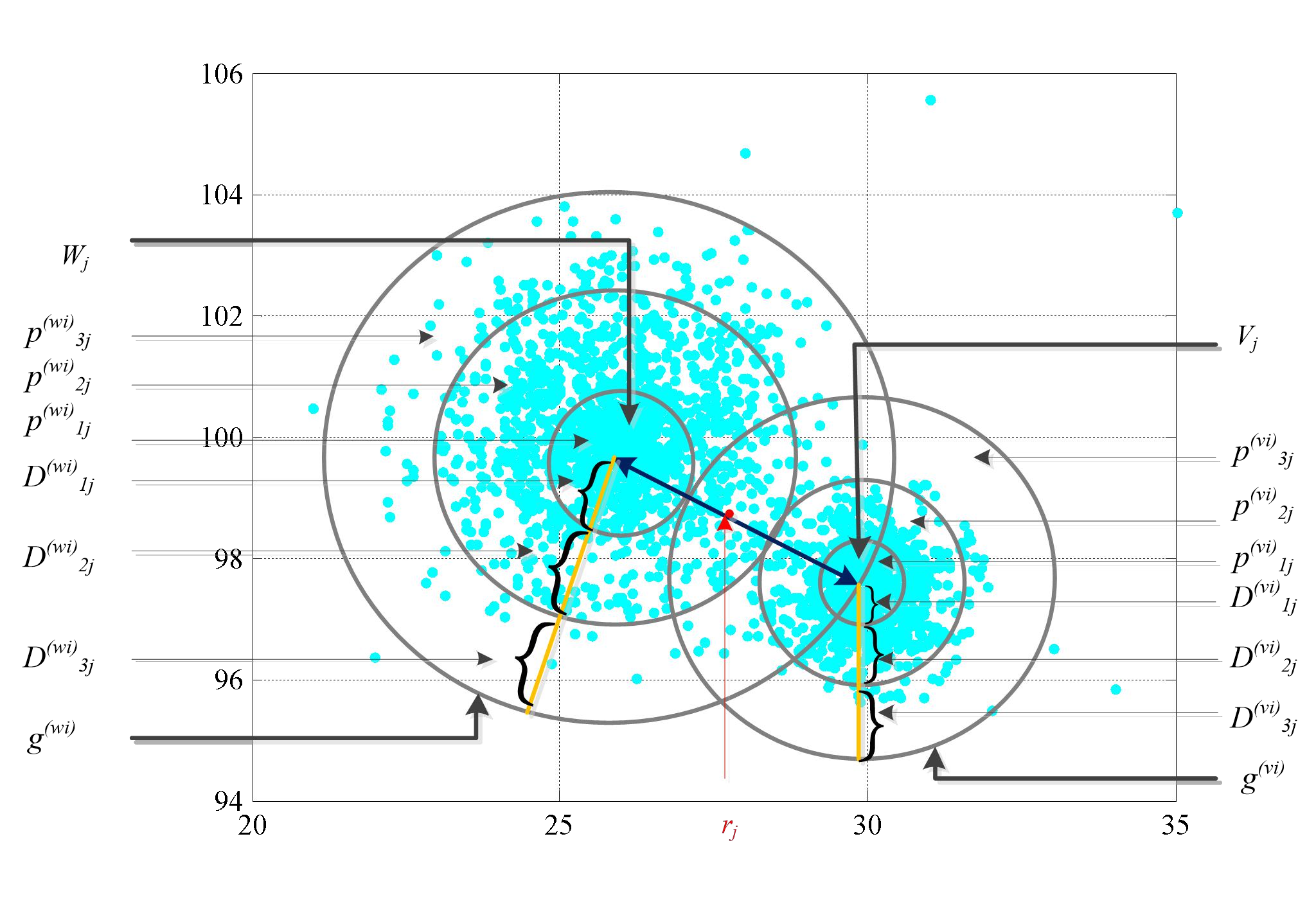
Unsupervised clustering algorithm can effectively reduce the dimension of high-dimensional unlabeled data, thus reducing the time and space complexity of data processing. However, the traditional clustering algorithm needs to set the upper bound of the number of categories in advance, and the deep learning clustering algorithm will fall into the problem of local optimum. In order to solve these problems, a probabilistic spatial clustering algorithm based on the Self Discipline Learning(SDL) model is proposed. The algorithm is based on the Gaussian probability distribution of the probability space distance between vectors, and uses the probability scale and maximum probability value of the probability space distance as the distance measurement judgment, and then determines the category of each sample according to the distribution characteristics of the data set itself. The algorithm is tested in Laboratory for Intelligent and Safe Automobiles(LISA) traffic light data set, the accuracy rate is 99.03%, the recall rate is 91%, and the effect is achieved.
翻译:不受监督的集群算法可以有效地减少高维无标签数据的维度,从而降低数据处理的时间和空间复杂性。然而,传统的集群算法需要事先设定类别数目的上限,而深学习的集群算法则则会成为当地最佳问题。为了解决这些问题,提议了基于自律学习模式的概率空间集群算法。该算法基于矢量之间空间距离概率的高斯概率分布,并使用概率空间距离的概率尺度和最大概率值作为距离测量判断,然后根据数据集本身的分布特点确定每个样本的类别。该算法在智能和安全汽车(LISA)交通光数据集实验室测试,精确率为99.03%,回溯率为91%,效果也实现了。