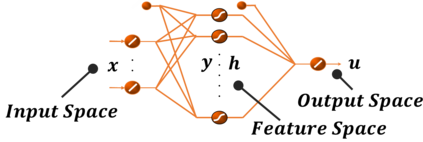
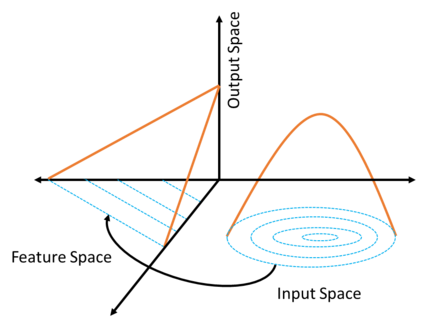
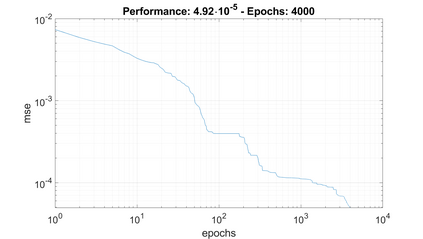
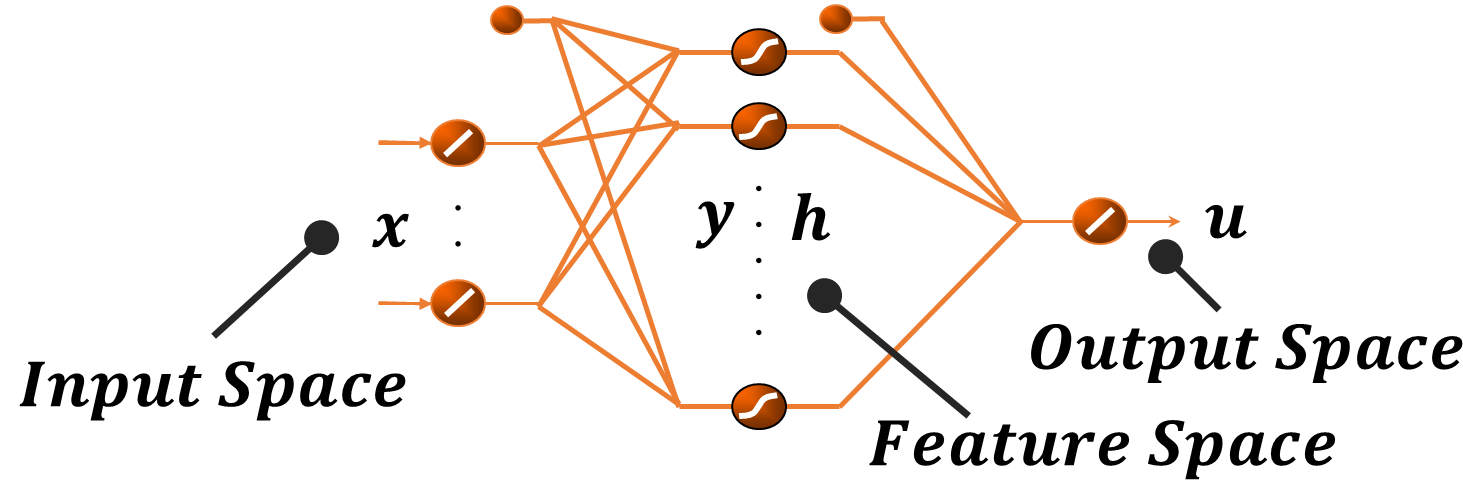
In this article an innovative method for training regressive MLP networks is presented, which is not subject to local minima. The Error-Back-Propagation algorithm, proposed by William-Hinton-Rummelhart, has had the merit of favouring the development of machine learning techniques, which has permeated every branch of research and technology since the mid-1980s. This extraordinary success is largely due to the black-box approach, but this same factor was also seen as a limitation, as soon more challenging problems were approached. One of the most critical aspects of the training algorithms was that of local minima of the loss function, typically the mean squared error of the output on the training set. In fact, as the most popular training algorithms are driven by the derivatives of the loss function, there is no possibility to evaluate if a reached minimum is local or global. The algorithm presented in this paper avoids the problem of local minima, as the training is based on the properties of the distribution of the training set, or better on its image internal to the neural network. The performance of the algorithm is shown for a well-known benchmark.
翻译:暂无翻译