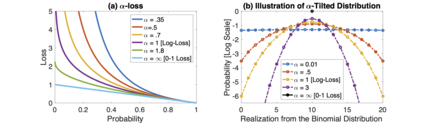
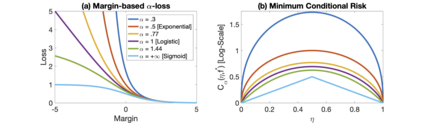
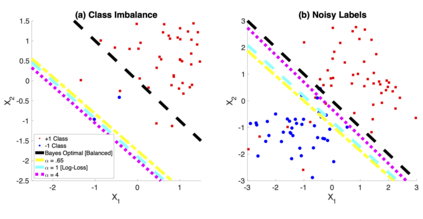
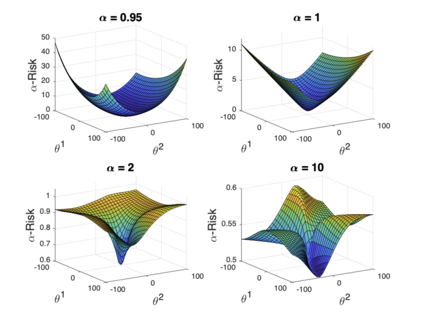
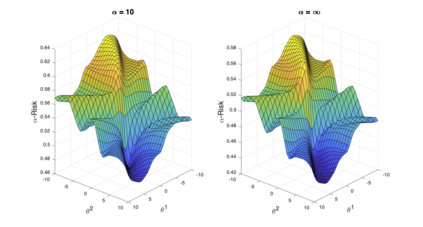
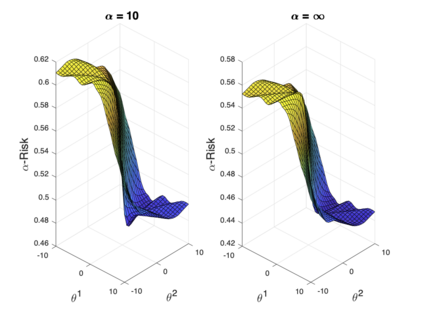
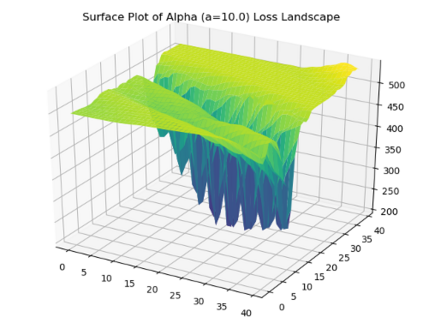
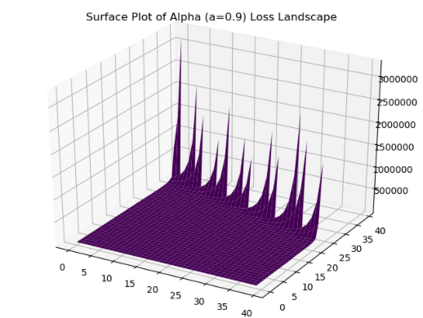
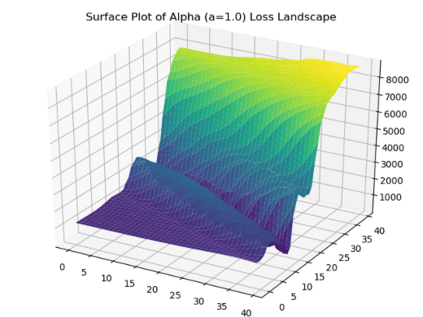
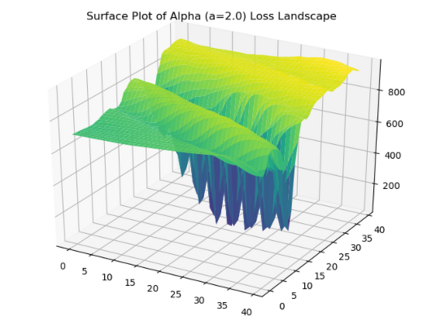
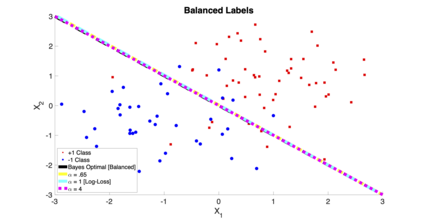
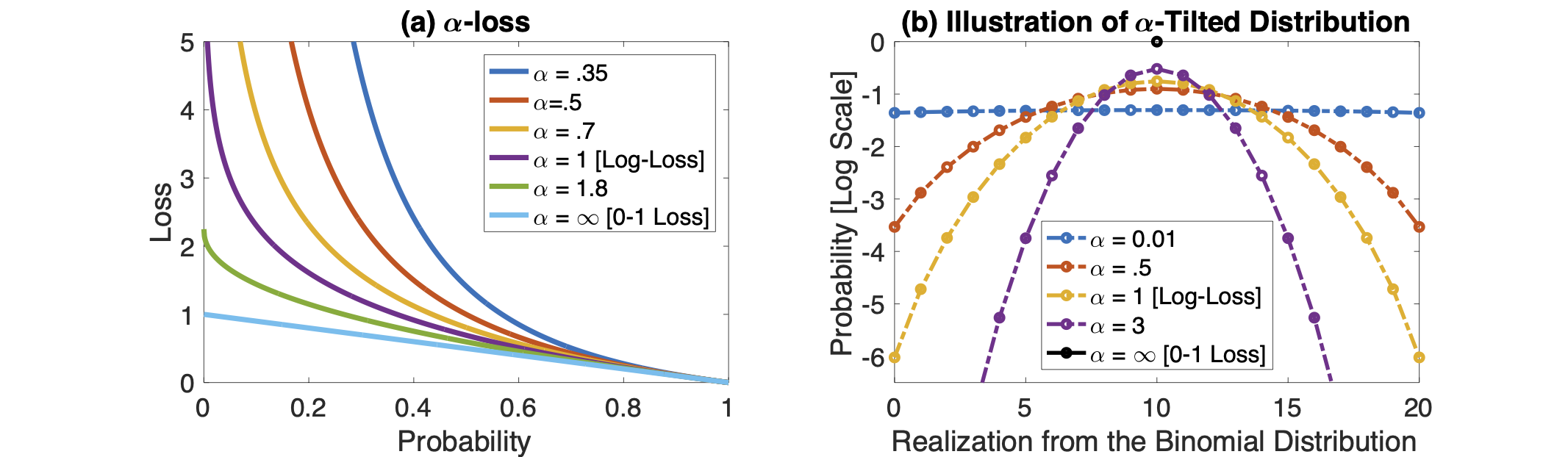
We introduce a tunable loss function called $\alpha$-loss, parameterized by $\alpha \in (0,\infty]$, which interpolates between the exponential loss ($\alpha = 1/2$), the log-loss ($\alpha = 1$), and the 0-1 loss ($\alpha = \infty$), for the machine learning setting of classification. Theoretically, we illustrate a fundamental connection between $\alpha$-loss and Arimoto conditional entropy, verify the classification-calibration of $\alpha$-loss in order to demonstrate asymptotic optimality via Rademacher complexity generalization techniques, and build-upon a notion called strictly local quasi-convexity in order to quantitatively characterize the optimization landscape of $\alpha$-loss. Practically, we perform class imbalance, robustness, and classification experiments on benchmark image datasets using convolutional-neural-networks. Our main practical conclusion is that certain tasks may benefit from tuning $\alpha$-loss away from log-loss ($\alpha = 1$), and to this end we provide simple heuristics for the practitioner. In particular, navigating the $\alpha$ hyperparameter can readily provide superior model robustness to label flips ($\alpha > 1$) and sensitivity to imbalanced classes ($\alpha < 1$).
翻译:我们引入了一个叫做 $ alpha$ 损失的金枪鱼损失函数, 以 $alpha = in ( 0,\ infty) 为参数, 在指数损失 (\ alpha = 1/2美元)、 日志损失 (\ alpha = 1美元) 和 0-1 损失 (\ alpha = 美元) 之间, 我们引入了一种叫作 $ alpha $ 损失 和 Arimoto 有条件的 entropy 之间的基本联系。 我们从理论上展示了 $ alpha 和 Arimotomoto 有条件的 entropy 之间的基本联系。 我们的主要实际结论是, 将 $ alpha $ 的敏感度校正调整, 以通过 Rademacher 复杂程度的概括技术来显示无症状的最佳性; 构建一个称为 严格当地准 准 的理念, 以量化 $ alpha- ftyle = 1, 我们在基准图像数据集上进行 的分类实验。