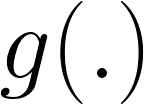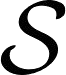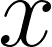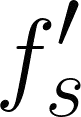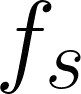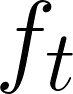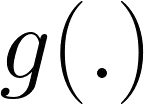Feature regression is a simple way to distill large neural network models to smaller ones. We show that with simple changes to the network architecture, regression can outperform more complex state-of-the-art approaches for knowledge distillation from self-supervised models. Surprisingly, the addition of a multi-layer perceptron head to the CNN backbone is beneficial even if used only during distillation and discarded in the downstream task. Deeper non-linear projections can thus be used to accurately mimic the teacher without changing inference architecture and time. Moreover, we utilize independent projection heads to simultaneously distill multiple teacher networks. We also find that using the same weakly augmented image as input for both teacher and student networks aids distillation. Experiments on ImageNet dataset demonstrate the efficacy of the proposed changes in various self-supervised distillation settings.
翻译:地貌回归是将大型神经网络模型蒸馏成较小的模型的简单方法。 我们显示,通过简单的网络结构变化,回归可以超越从自我监督模型中进行知识蒸馏的更为复杂的先进方法。 令人惊讶的是,在CNN主干中添加多层感官头即使只在蒸馏过程中使用,并丢弃在下游任务中也是有益的。 因此,更深的非线性预测可以在不改变推理结构和时间的情况下用于准确模仿教师。 此外,我们利用独立投影头同时蒸馏多个教师网络。 我们还发现,使用同样微弱的放大图像作为师生网络的输入来帮助蒸馏。 图像网络数据集实验显示了各种自我监督蒸馏环境中拟议变化的功效。