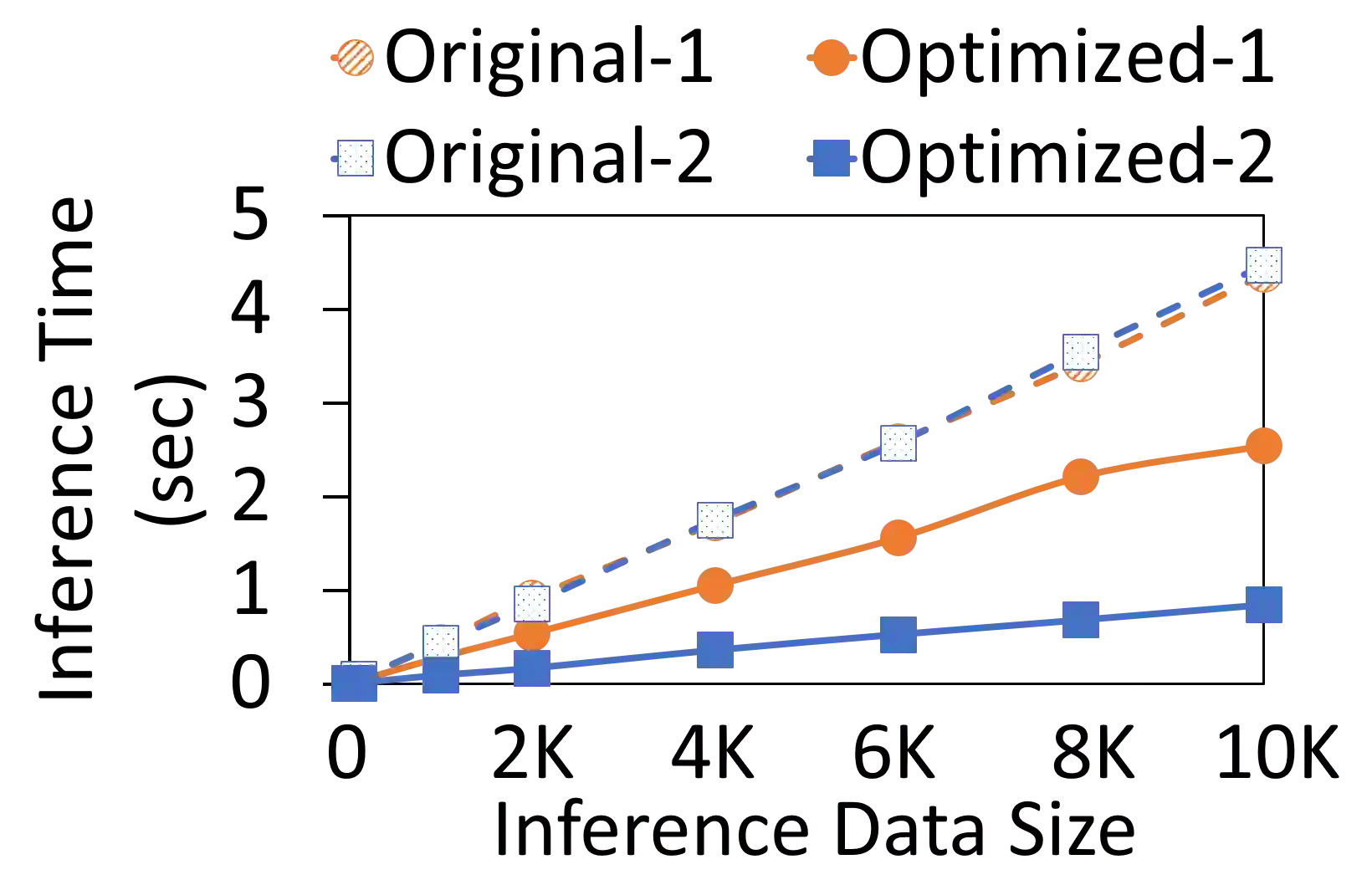
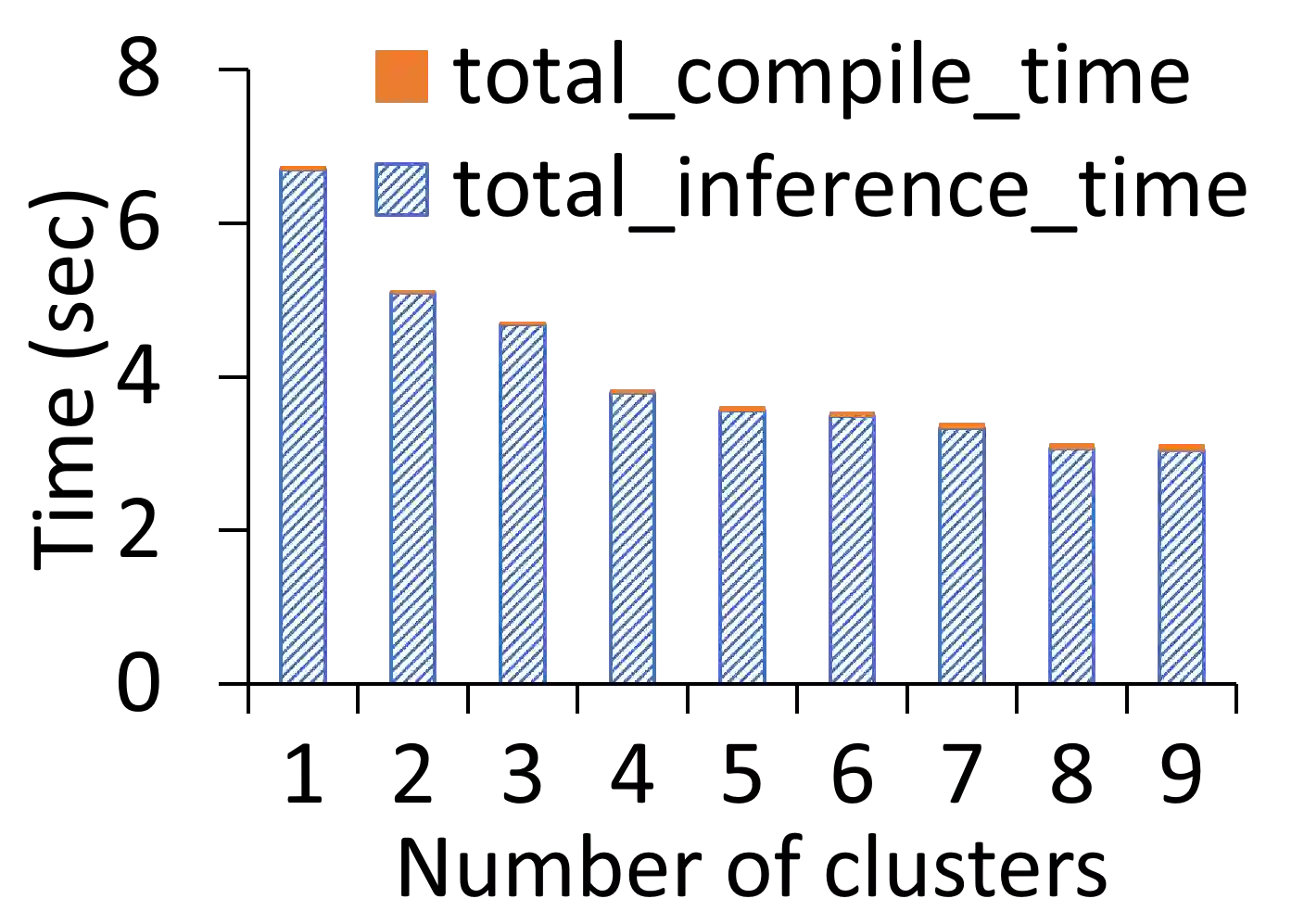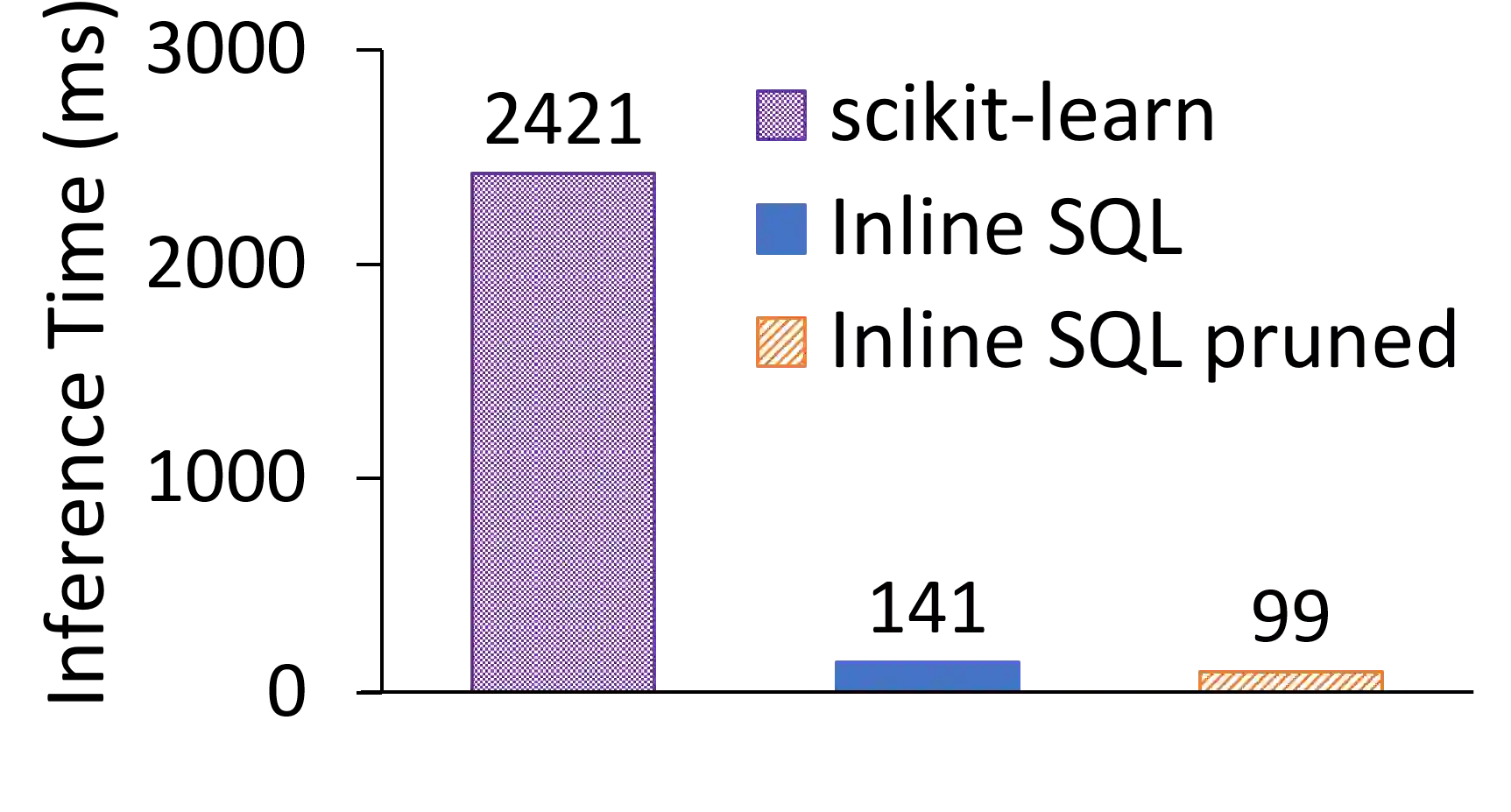The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.
翻译:在企业中扩大采用机器学习正在加大严格治理和成本效益业绩的压力,特别是模型存储和推导的共同和相应步骤的典型存储和推导的常见和相应步骤。鉴于其快速数据存取和处理的成熟基础设施,以及企业特征的支持(例如加密、审计、高可用性),RDBMS提供了一个自然的起点。为了利用上述所有因素,我们需要解决一个关键问题:在RBMS中,RBMS评分ML模型的匹配(不完善?)专用框架的性能?我们积极响应上述要求的是建设Raven,这是一个在SQL服务器深处利用ML运行时间(即ONNX运行时间)本地集成的系统,以及统一的中间代表(IR),使ML和DB运营商之间能够进行先进的交叉优化。在这个优化空间,我们发现将DB/Compiler/ML模型的思维结合起来的最令人兴奋的研究机会。我们对真实数据的初步评估表明,在SQL实况服务器上本土集成ML的实绩达5.5x上取得业绩收益。