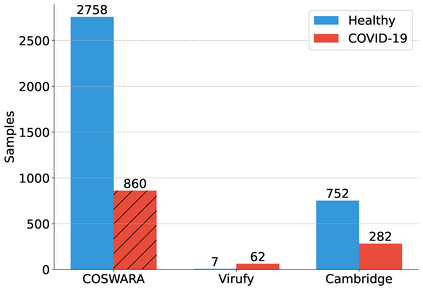
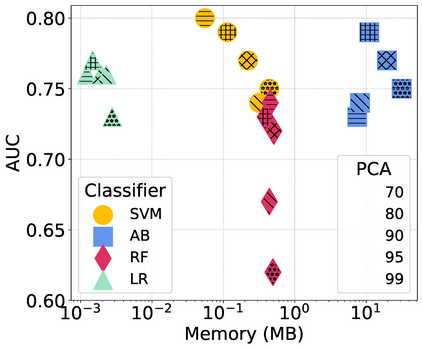
Smartphones and wearable devices, along with Artificial Intelligence, can represent a game-changer in the pandemic control, by implementing low-cost and pervasive solutions to recognize the development of new diseases at their early stages and by potentially avoiding the rise of new outbreaks. Some recent works show promise in detecting diagnostic signals of COVID-19 from voice and coughs by using machine learning and hand-crafted acoustic features. In this paper, we decided to investigate the capabilities of the recently proposed deep embedding model L3-Net to automatically extract meaningful features from raw respiratory audio recordings in order to improve the performances of standard machine learning classifiers in discriminating between COVID-19 positive and negative subjects from smartphone data. We evaluated the proposed model on 3 datasets, comparing the obtained results with those of two reference works. Results show that the combination of L3-Net with hand-crafted features overcomes the performance of the other works of 28.57% in terms of AUC in a set of subject-independent experiments. This result paves the way to further investigation on different deep audio embeddings, also for the automatic detection of different diseases.
翻译:智能手机和可磨损装置,连同人工智能,可以通过实施低成本和普遍的解决办法,在新疾病的早期发现新疾病的发病,并有可能避免新爆发的出现,从而在大流行病控制中代表一种游戏变革。最近的一些工作显示,通过使用机器学习和手工制作的声学特征,从声音和咳嗽中检测COVID-19的诊断信号有希望。在这份文件中,我们决定调查最近提出的深入嵌入模型L3-Net的能力,以便从原始呼吸录音中自动提取有意义的特征,从而改进标准机器学习分类员在区分智能电话数据中的COVID-19阳性与负性主题方面的性能。我们评估了3个数据集的拟议模型,将所获得的结果与两个参考著作的结果进行比较。结果显示,L3-Net与手工艺特征的结合克服了其他28.57%的AUC在一系列依赖主题的实验中的性能。这为进一步调查不同深度的音频嵌入情况铺平了道路,也是为了自动检测不同疾病。