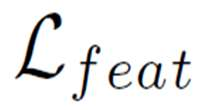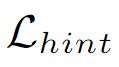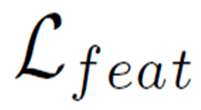Large-scale speech self-supervised learning (SSL) has emerged to the main field of speech processing, however, the problem of computational cost arising from its vast size makes a high entry barrier to academia. In addition, existing distillation techniques of speech SSL models compress the model by reducing layers, which induces performance degradation in linguistic pattern recognition tasks such as phoneme recognition (PR). In this paper, we propose FitHuBERT, which makes thinner in dimension throughout almost all model components and deeper in layer compared to prior speech SSL distillation works. Moreover, we employ a time-reduction layer to speed up inference time and propose a method of hint-based distillation for less performance degradation. Our method reduces the model to 23.8% in size and 35.9% in inference time compared to HuBERT. Also, we achieve 12.1% word error rate and 13.3% phoneme error rate on the SUPERB benchmark which is superior than prior work.
翻译:大型语音自我监督学习(SSL)已经出现在语言处理的主要领域,然而,由于语言处理的庞大规模而引发的计算成本问题给学术界造成了很大的进入障碍。此外,现有的语音 SSL 模型蒸馏技术通过减少层层压缩模型,这导致语音识别(PR)等语言模式任务性能退化。在本文中,我们提议FitHuBERT,它使几乎所有模型组件的尺寸都变薄,与先前的语音SSL 蒸馏工程相比,层的尺寸更深。此外,我们使用一个时间缩减层来加快推导时间,并提出一种基于提示的蒸馏方法,以降低性能退化。我们的方法将模型的尺寸减少到23.8%,比HuBERT低35.9%。此外,我们在SUPERB基准上实现了12.1%的字误差率和13.3%的电话错误率,该基准比以前的工作要高。