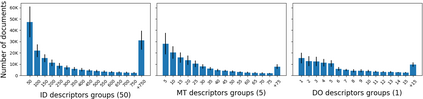
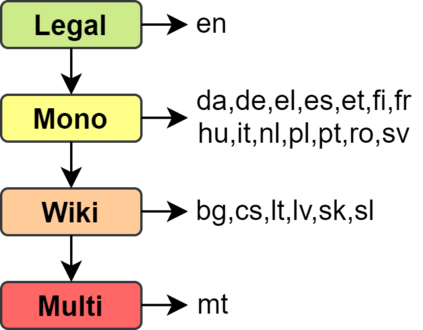
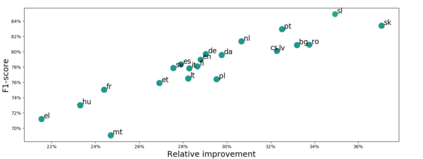
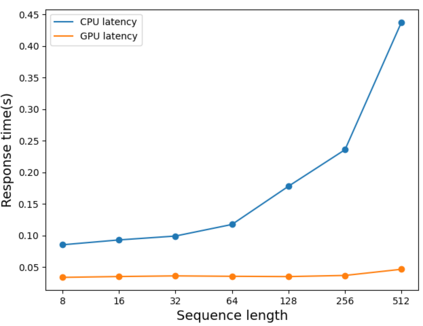
EuroVoc is a multilingual thesaurus that was built for organizing the legislative documentary of the European Union institutions. It contains thousands of categories at different levels of specificity and its descriptors are targeted by legal texts in almost thirty languages. In this work we propose a unified framework for EuroVoc classification on 22 languages by fine-tuning modern Transformer-based pretrained language models. We study extensively the performance of our trained models and show that they significantly improve the results obtained by a similar tool - JEX - on the same dataset. The code and the fine-tuned models were open sourced, together with a programmatic interface that eases the process of loading the weights of a trained model and of classifying a new document.
翻译:EuroVoc是一个多语种的术语词库,是为组织欧洲联盟机构的立法文件而建造的,它包括了数千个不同具体程度的类别,其说明以近30种语言的法律文本为对象;在这项工作中,我们提议了22种语言的EuroVoc分类统一框架,通过微调基于现代变压器的预先培训语言模型进行微调;我们广泛研究我们经过培训的模型的性能,并表明它们大大改进了同一数据集上类似工具JEX获得的结果;代码和经过精细调整的模型是开放的,同时有一个方案界面,可以减轻经过培训的模型的重量和新文件的分类过程。