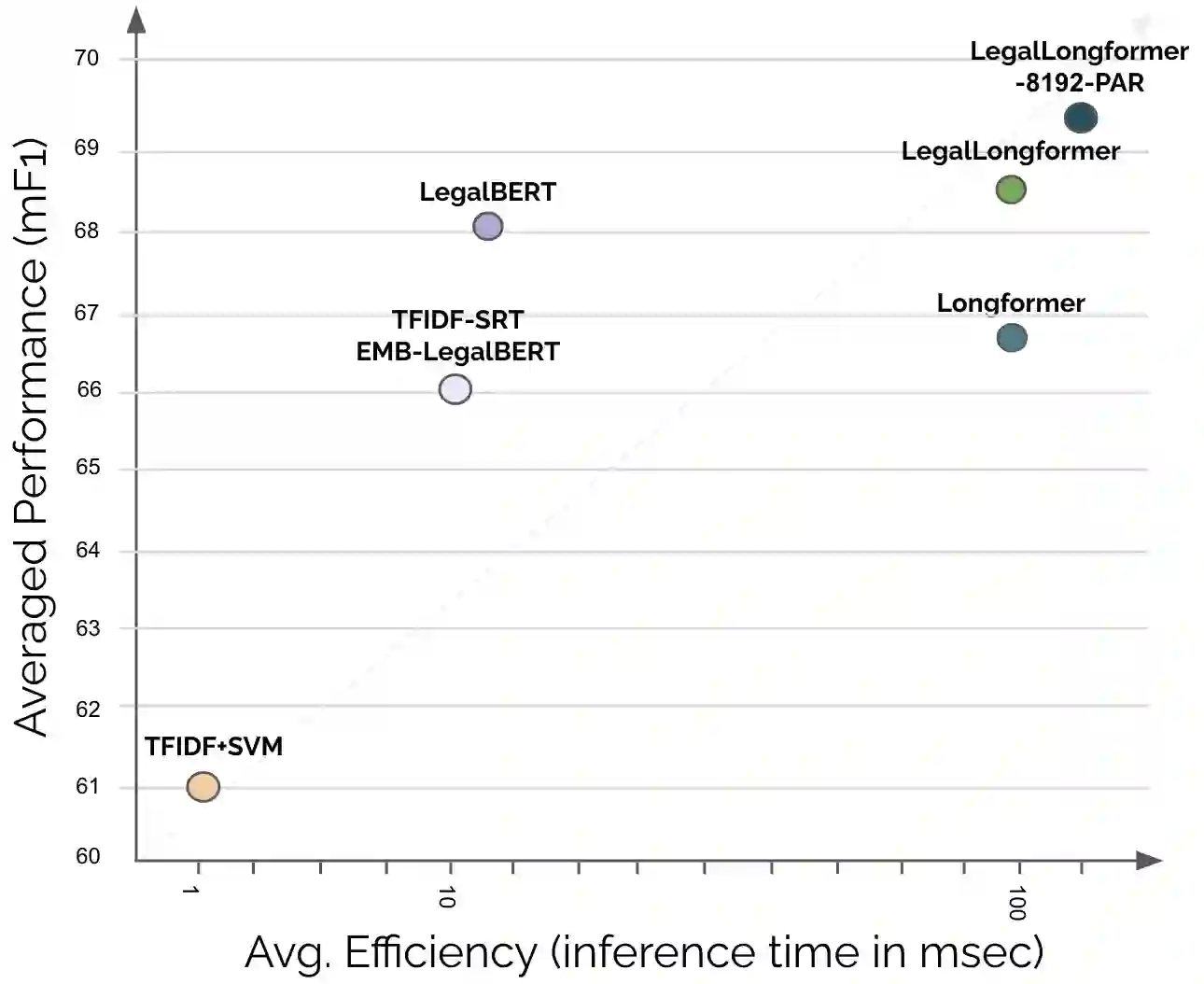
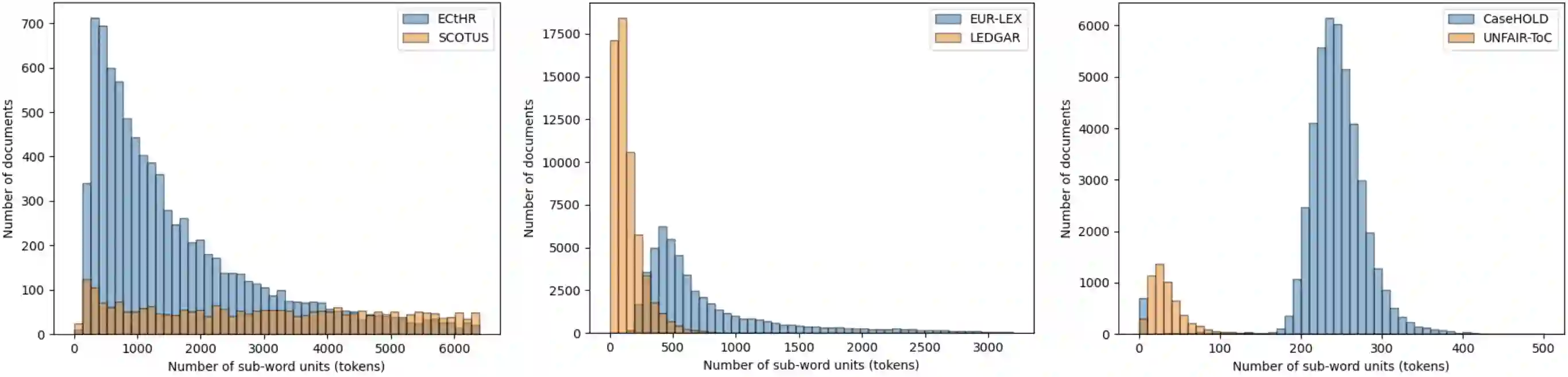
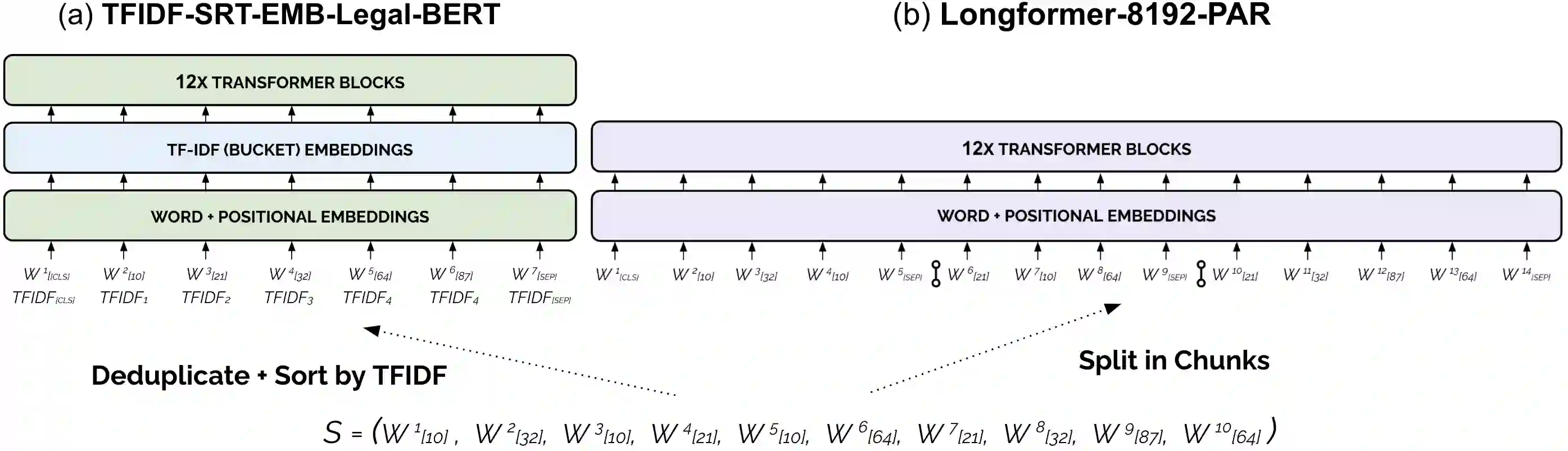
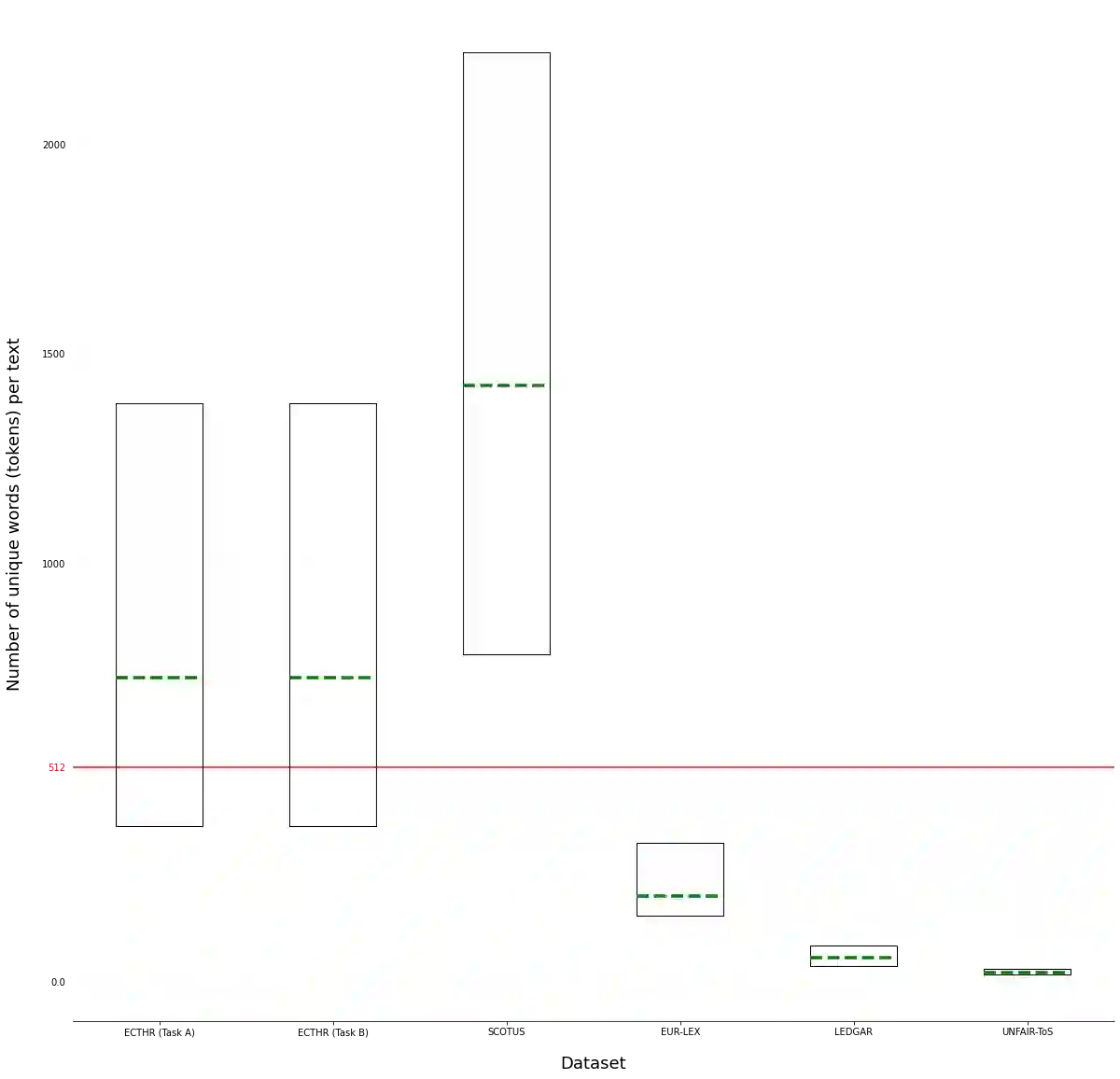
Pre-trained Transformers currently dominate most NLP tasks. They impose, however, limits on the maximum input length (512 sub-words in BERT), which are too restrictive in the legal domain. Even sparse-attention models, such as Longformer and BigBird, which increase the maximum input length to 4,096 sub-words, severely truncate texts in three of the six datasets of LexGLUE. Simpler linear classifiers with TF-IDF features can handle texts of any length, require far less resources to train and deploy, but are usually outperformed by pre-trained Transformers. We explore two directions to cope with long legal texts: (i) modifying a Longformer warm-started from LegalBERT to handle even longer texts (up to 8,192 sub-words), and (ii) modifying LegalBERT to use TF-IDF representations. The first approach is the best in terms of performance, surpassing a hierarchical version of LegalBERT, which was the previous state of the art in LexGLUE. The second approach leads to computationally more efficient models at the expense of lower performance, but the resulting models still outperform overall a linear SVM with TF-IDF features in long legal document classification.
翻译:培训前的变压器目前控制着大多数NLP任务,但是对最大输入长度(BERT中的512个子字)施加限制,这些限制在法律领域限制太强。即使是Longfore和BigBird等少见的注意模式,将最大输入长度提高到4 096个小字,在LexGLUE的六套数据集中,有六套数据集中的三套中严重删除文本。具有TF-IDF特点的简单线性分类器可以处理任何长度的文本,需要远小于培训和部署的资源,但通常由预先培训的变压器完成。我们探索了两种方向来应对长期的法律文本。我们探索了两种方向:(一)修改从Leganexew和BIBird开始的长期热量模型,以便处理更长的文本(最多为8 192个子字),以及(二)修改LegaBERTF,以便使用TF-IDF的表述方式。第一种是最佳的绩效,超过LEBERT的等级版本,这是LEGLEPERT的原版,这是LGLLPERUE的工艺状态。第二种方法导致计算效率更高的模式,在计算中以较低的模式中以较低性模式,但是仍然以降低了整个文件格式的立式格式。