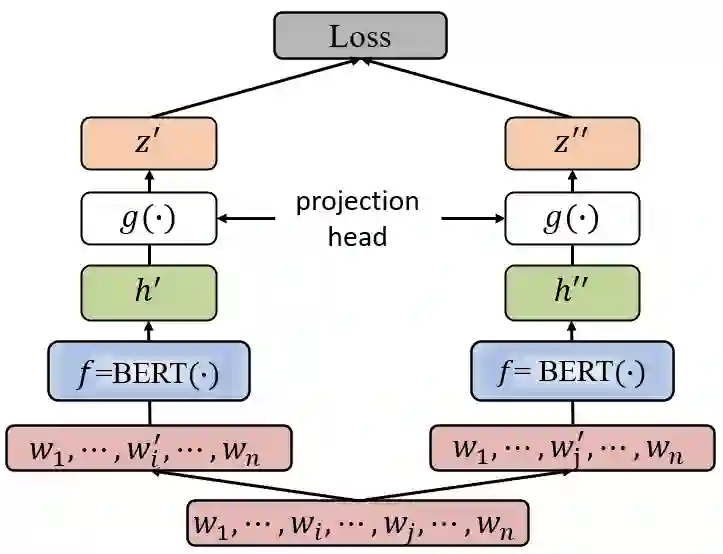
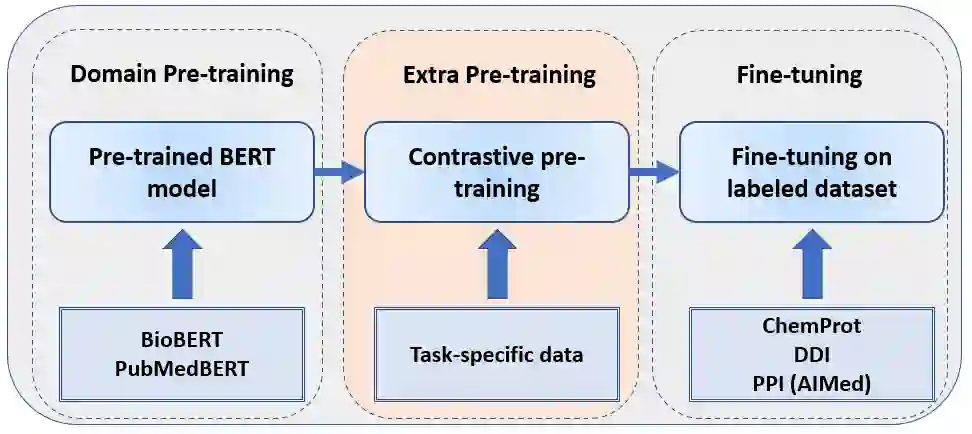
Contrastive learning has been used to learn a high-quality representation of the image in computer vision. However, contrastive learning is not widely utilized in natural language processing due to the lack of a general method of data augmentation for text data. In this work, we explore the method of employing contrastive learning to improve the text representation from the BERT model for relation extraction. The key knob of our framework is a unique contrastive pre-training step tailored for the relation extraction tasks by seamlessly integrating linguistic knowledge into the data augmentation. Furthermore, we investigate how large-scale data constructed from the external knowledge bases can enhance the generality of contrastive pre-training of BERT. The experimental results on three relation extraction benchmark datasets demonstrate that our method can improve the BERT model representation and achieve state-of-the-art performance. In addition, we explore the interpretability of models by showing that BERT with contrastive pre-training relies more on rationales for prediction. Our code and data are publicly available at: https://github.com/udel-biotm-lab/BERT-CLRE.
翻译:在计算机视野中,利用对比学习来学习高品质的图像,然而,在自然语言处理中,由于缺少一种一般的文本数据增强方法,对比学习没有被广泛使用。在这项工作中,我们探索了利用对比学习的方法来改进BERT模型的文本体现方式,以便从BERT模型中提取关系。我们框架的关键节点是一个独特的对比性培训前步骤,通过将语言知识无缝地纳入数据扩充,为相关提取任务量身定制。此外,我们调查了从外部知识库中构建的大规模数据如何能够加强BERT的对比性预培训的一般性。三个关联性提取基准数据集的实验结果表明,我们的方法可以改进BERT模型的表述方式,并实现最先进的性能。此外,我们探索模型的可解释性,显示BERT与对比性预培训更多地依赖于预测的理由。我们的代码和数据公布在https://github.com/udel-bioitm-lab/BERT-CLRE。