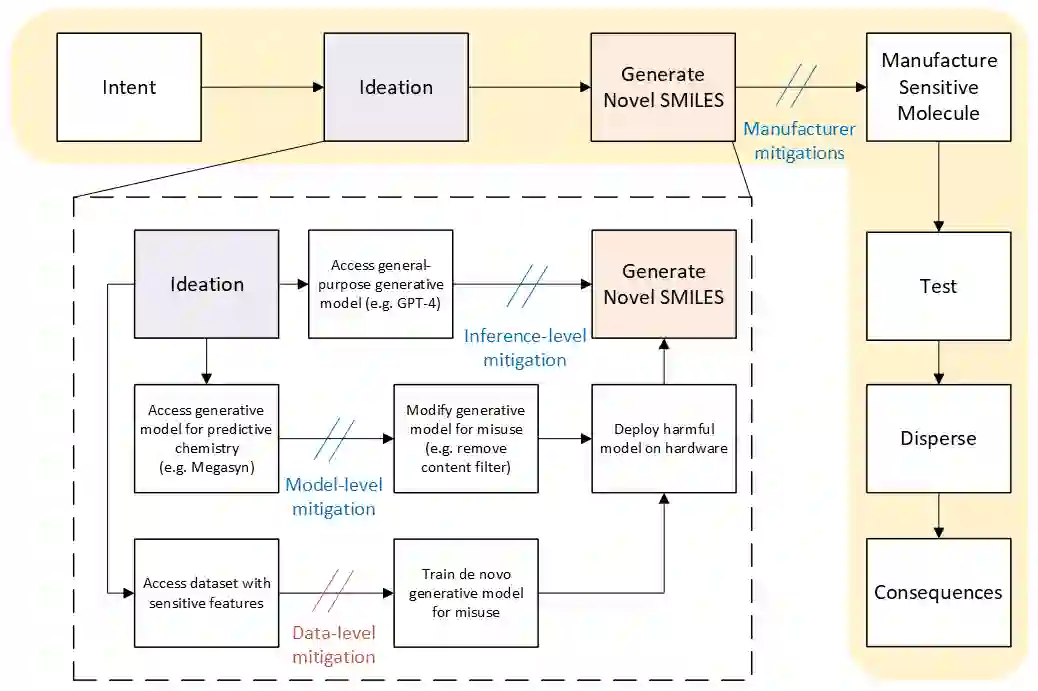
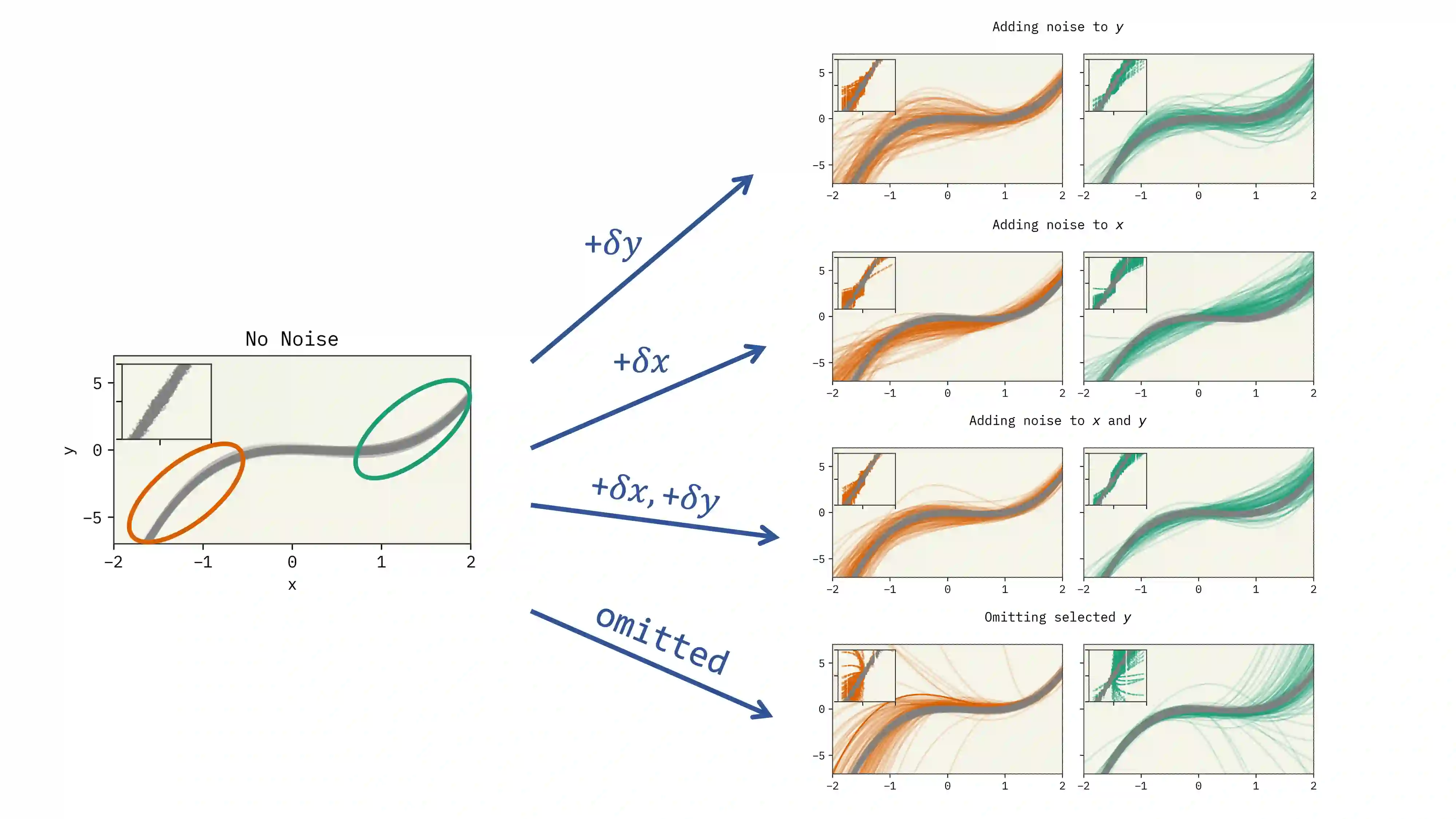
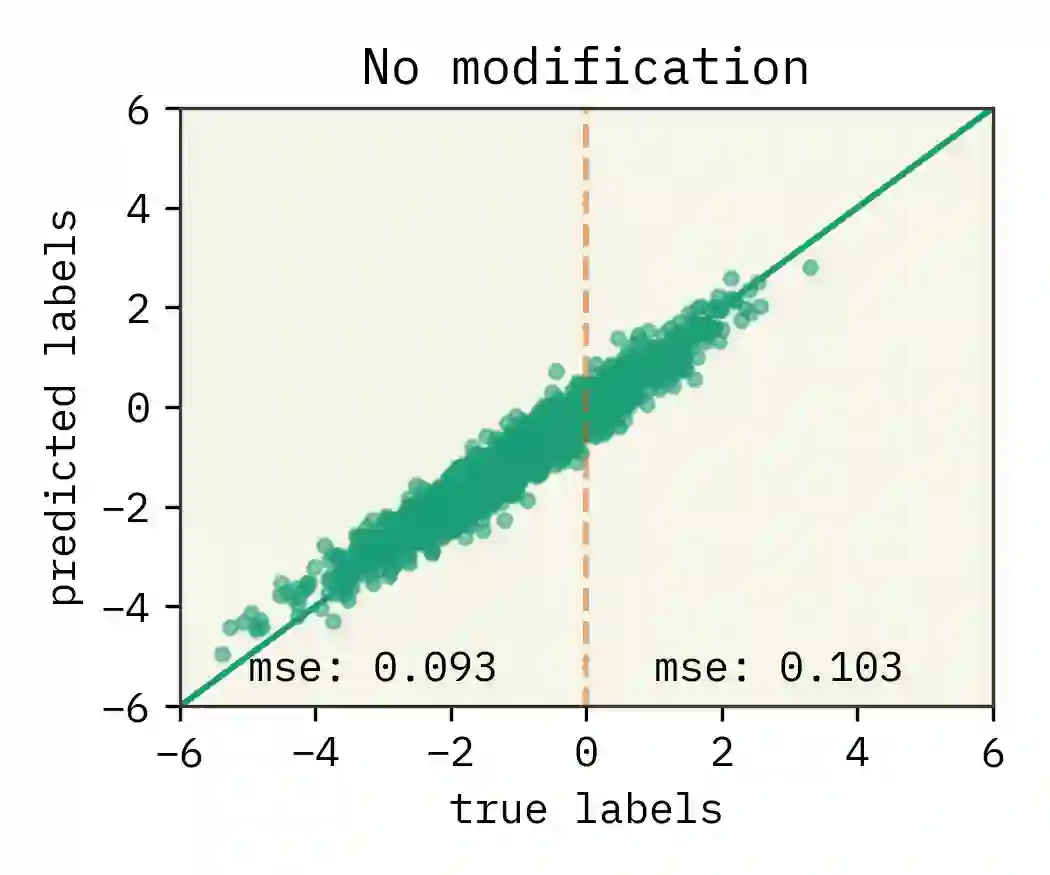
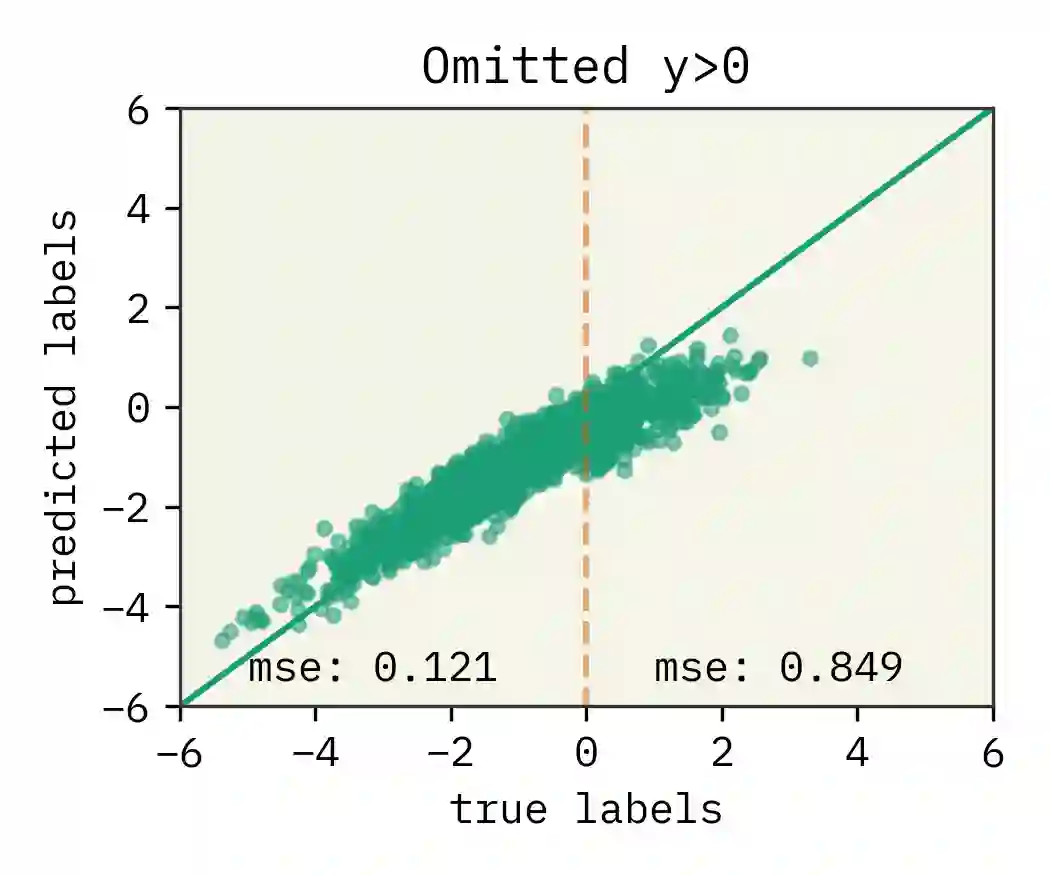
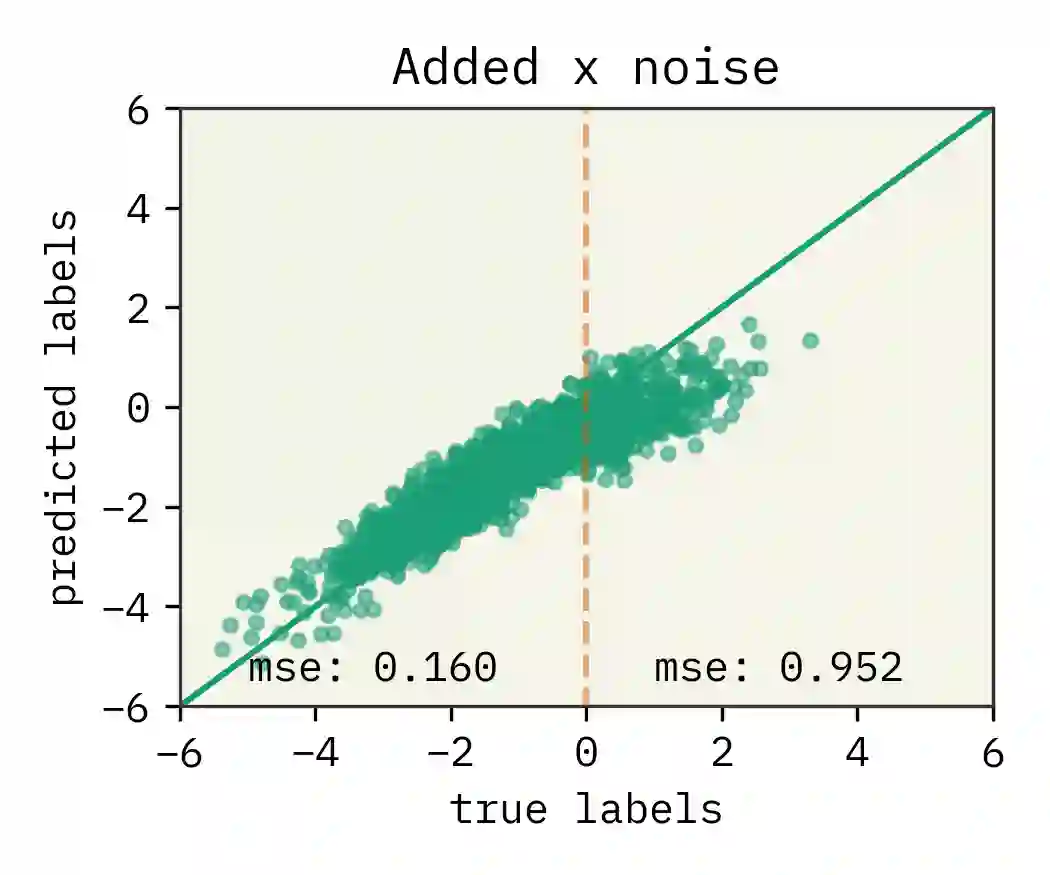
The dual use of machine learning applications, where models can be used for both beneficial and malicious purposes, presents a significant challenge. This has recently become a particular concern in chemistry, where chemical datasets containing sensitive labels (e.g. toxicological information) could be used to develop predictive models that identify novel toxins or chemical warfare agents. To mitigate dual use risks, we propose a model-agnostic method of selectively noising datasets while preserving the utility of the data for training deep neural networks in a beneficial region. We evaluate the effectiveness of the proposed method across least squares, a multilayer perceptron, and a graph neural network. Our findings show selectively noised datasets can induce model variance and bias in predictions for sensitive labels with control, suggesting the safe sharing of datasets containing sensitive information is feasible. We also find omitting sensitive data often increases model variance sufficiently to mitigate dual use. This work is proposed as a foundation for future research on enabling more secure and collaborative data sharing practices and safer machine learning applications in chemistry.
翻译:机器学习应用的双重使用(模型可用于有益和恶意目的)为人工智能领域提出了重要挑战。在化学领域,化学数据集包含敏感标签(例如,毒理信息),可能被用来开发预测模型,以识别新型毒素或化学战剂,因此最近成为特别关注的问题之一。我们提出了一种模型无关的方法,通过有选择的加噪来保护训练深度神经网络的数据在有益区域内所具有的信息无损的同时降低双重使用风险。我们评估了所提出方法在最小二乘法、多层感知机和图形神经网络上的有效性。我们的研究结果表明,有选择的加噪可以增加模型方差和偏差,并导致控制下敏感标签预测的方差增加,因此数据集的保护共享是可行的;我们发现忽略敏感数据往往使模型的方差增加足以降低双重使用风险。这项研究为未来研究提供了基础,能够促进更加安全和协作性的数据共享实践以及更加安全的化学机器学习应用。