
论文题目:Variational Inference for Training Graph Neural Networks in Low-Data Regime through Joint Structure-Label Estimation
作者信息:劳丹宁*,杨新宇*,吴齐天,严骏驰 论文链接:https://dl.acm.org/doi/10.1145/3534678.3539283(可点击阅读原文查看) 代码链接:https://github.com/Thinklab-SJTU/WSGNN
研究动机与背景
现有的图神经网络(GNN)方法普遍具有依赖于精密的输入数据(包括完整而正确的图结构,充分的节点特征和节点标签等)的特性,在输入数据有缺失,有噪声,不完美时,其模型预测表现就会大大下降。然而在实际应用中,囿于现实因素的影响,比如巨大的人力成本下数据标签搜集的难度,抑或是隐式潜在的链接难以搜集,用于建模的图数据往往是不够完整充分的,甚至有可能出现已知的节点标签和连边都很少的情况,而此时大部分图神经网络方法就变得力不从心。如下图所示,我们模拟了已知的连边数量从80%到1%,已知的节点标签数量从每类20个到每类只有1个的情况,测量了GCN[1]和GAT[2]在每种情况下在节点分类(NC)和链接预测(LP)两个任务上的表现,可视地展现了其网络性能逐渐变差,预测失效的情况。

过去的半监督方法只能解决“大已知,小未知”条件下的推断。当初始信息给定不足(例如图节点中已知的标签数量变少,图结构中已知的边变少),如何实现对极少的监督信息的最大化利用,在“小已知,大未知”的弱监督条件下仍能延续模型的优秀表现,仍然是一个艰巨的挑战。为了解决这个问题,我们提出了一种基于变分推断的弱监督图神经网络模型WSGNN,结合了图表示学习和图结构学习的思想,有效地实现了基于有限标记下的外推和泛化。与过往的半监督抑或弱监督方法[3-4]最不同的是,我们首次关注了连边和标签同时缺失的情况,也因此使得我们的模型具有更广泛的应用场景以及更强的鲁棒性。
方法
问题建模
我们将节点半监督(Node SSL)和连边半监督(Edge SSL)的场景融合在一起,将上一小节中提到的问题建模为:利用已知的少量标签和不完整的图结构进行训练,同时实现大量标签未知的节点的分类任务(node classification)和大量隐藏连边的预测任务(link prediction)。
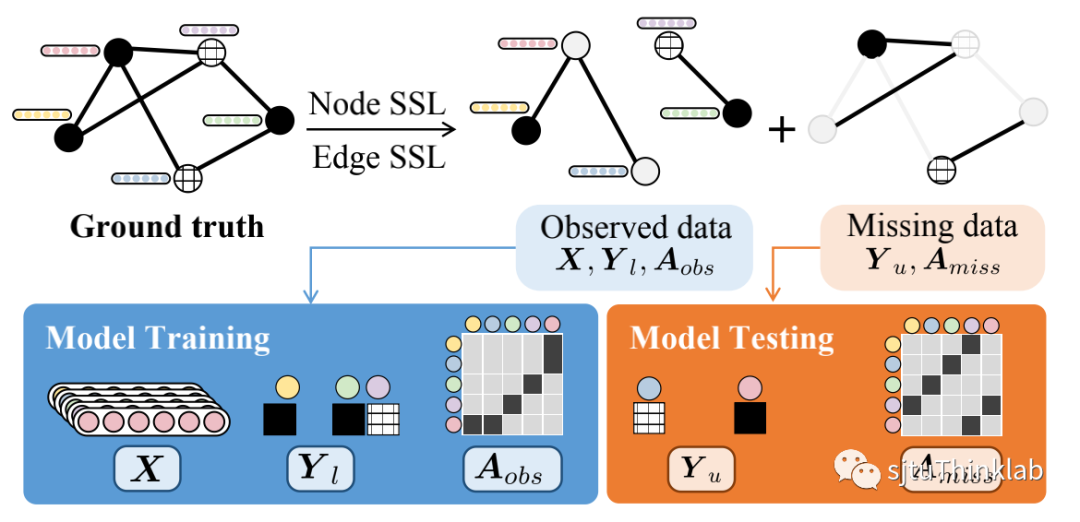
**变分推断和证据下界(Variational Inference and Evidence Lower Bound)
我们的模型框架是基于变分推断原则的,其中是未知的潜在变量,而是已知的变量。为了估计不可计算的后验分布,我们引入了识别模型(recognition model),代表分布。于是,证据下界的表示如下所示。
实际上,通过将实例化为一个深度网络,将实例化为另一个网络,我们可获得最优参数。
另外,我们也可以将证据下界表示成KL散度的形式,用分布间距离来理解优化过程。 在接下来的篇幅中,我们将介绍我们是如何用基于联合学习的双线模型去实例化两个分布,学习得模型特征,图结构,以及网络参数的。
双线模型
我们提出了一种联合预测节点标签和图结构的新框架,将传统图神经网络模块和图结构学习模块内嵌到分支结构中。通过迭代地学习节点表示和图结构,实现二者的共同优化。
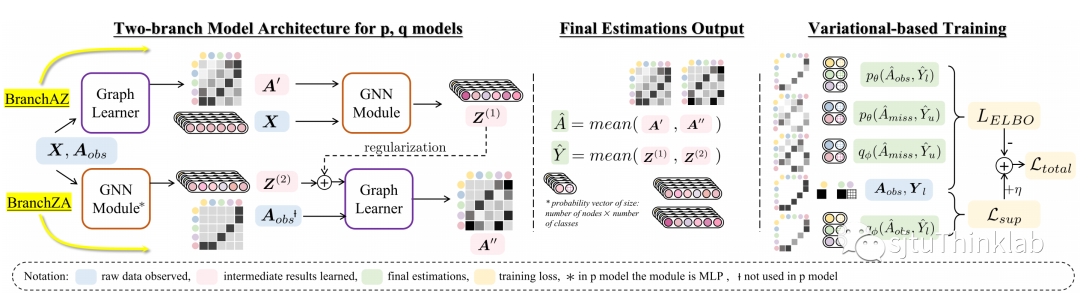
首先,基于联合学习的基本假设——更好的图结构来源于更好的表示,反之亦然,我们提出了两个对应的分支。分别是在原始图基础上进行图表示学习而后改进图结构(BranchZA),以及先进行图结构学习以期获得更精细的节点表示(BranchAZ)。为了减少不完整初始图结构对表示学习的影响,我们额外引入了分支间交互作为规约,额外补充信息(图中所示regularization)。进一步地,经过两个分支双层模块的表示-结构联合学习,我们融合不同层的结果而得到最终的预测。通过分别将该联合预测模型作为变分推断方法中和的实例化网络,我们给出了联合学习场景下的模型训练方法。

实验结果
**社交网络数据集
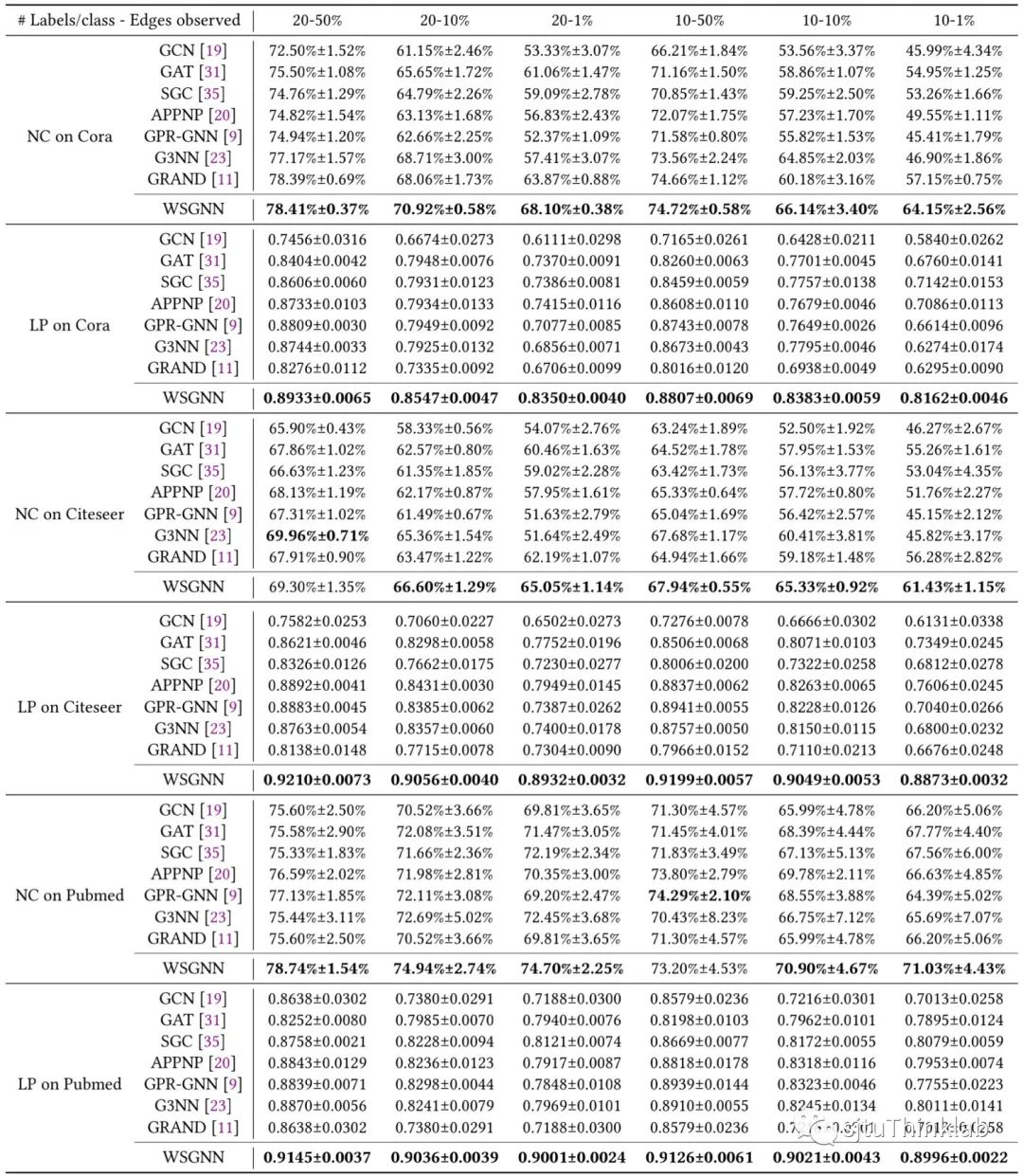
**1)主实验(常规数据缺失):**我们在常用的社交网络数据集Cora,CiteSeer,PubMed上进行了广泛的节点分类(NC)和链接预测(LP)试验,比较了多种图神经网络算法,模拟了从数据较为充足到数据相对缺失的各种情况。如下所示,我们的方法WSGNN取得了全面的超越性结果。
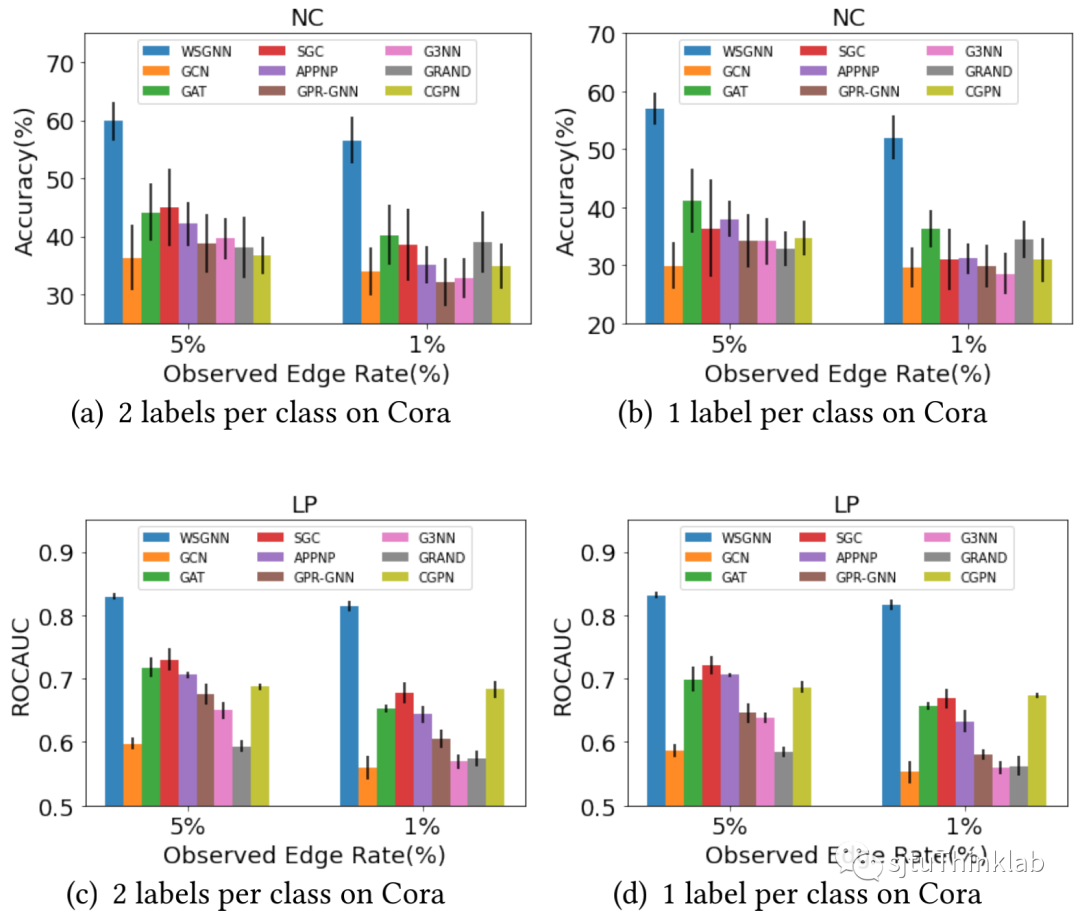
**2)极端数据缺失场景(Extreme Low Data Regime):**我们也在Cora数据集上展示了只有5%或1%的连边可见,每一类只有1个/2个已知标签的极端数据缺失情况。如下所示,我们的方法WSGNN取得了压倒性优势。
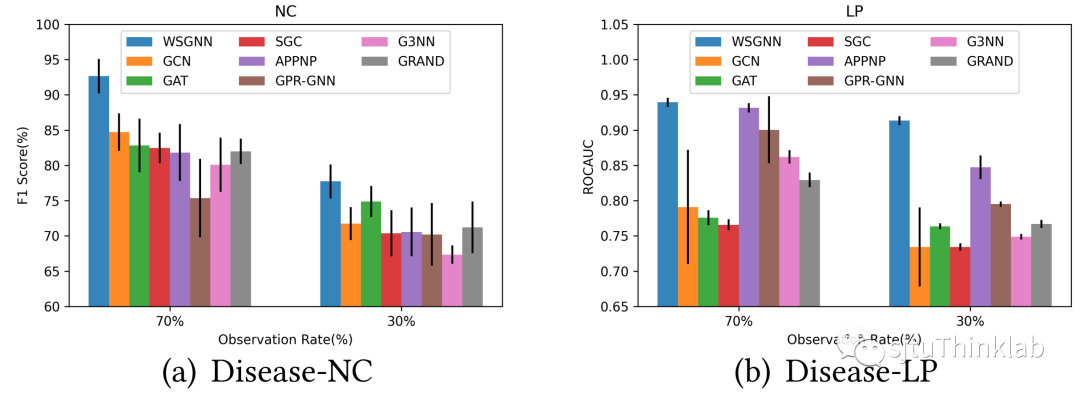
**案例分析:疾病传播数据集
同样的,我们在疾病传播数据集上对数据缺失场景分别测试了节点分类和链接预测的任务。在Disease-NC上,我们完成了节点分类,在Disease-LP上我们完成了链接预测。结果表示,即使在做独立预测的情况下,我们的模型WSGNN仍然取得了超过所有基线方法的良好效果。
**可视化
我们将在Cora数据集上,使用已知标签数量为20个/类,已知边数量为1%的信息去训练得到的节点表征,以及只使用1个/类的标签和1%边去训练得到的节点表征可视化如下图。将两种情况对比可知,即使在监督信息比较丰富的半监督环境中,基线方法尚能取得较为满意的结果,在极端弱监督条件下,基线方法也或多或少失去了将节点分类的能力,而我们的模型WSGNN要鲁棒得多。

未来展望
我们计划从理论上有针对性地进一步丰富缺失数据带来的推断假设,同时在不同的弱监督应用场景上进一步扩展我们模型的实用性。如果您对我们的工作感兴趣,欢迎联系sjtuldn@sjtu.edu.cn / laodanning@sjtu.edu.cn。
参考文献
[1] Thomas Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR. [2] Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio’, and Yoshua Bengio. 2018. Graph Attention Networks. In ICLR. [3] Sheng Wan, Yibing Zhan, Liu Liu, Baosheng Yu, Shirui Pan, and Chen Gong. 2021. Contrastive Graph Poisson Networks: Semi-Supervised Learning with Extremely Limited Labels. In NeurIPS. [4] Wanyu Lin, Zhaolin Gao, and Baochun Li. 2020. Shoestring: Graph-Based Semi Supervised Classification With Severely Limited Labeled Data. In CVPR. 4173–4181. [5] Ines Chami, Rex Ying, Christopher Ré, and Jure Leskovec. 2019. Hyperbolic Graph Convolutional Neural Networks. In NeurIPS, Vol. 32. 4869–4880.

