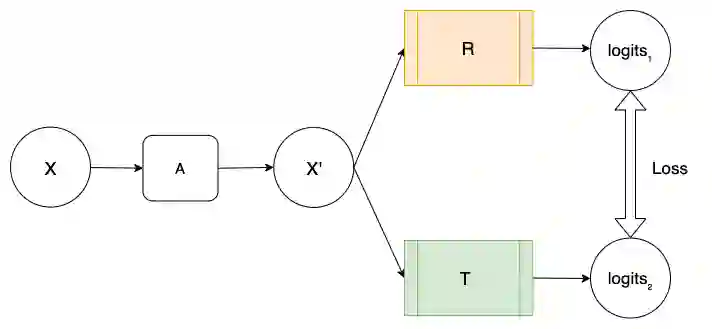
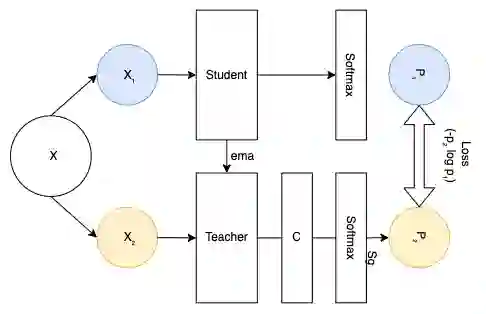
Recent advances in deep learning and computer vision have reduced many barriers to automated medical image analysis, allowing algorithms to process label-free images and improve performance. Specifically, Transformers provide a global perspective of the image, that Convolutional Neural Networks (CNNs) inherently lack. Here we present Cross Architectural - Self Supervision, a novel self-supervised learning approach that leverages Transformer and CNN simultaneously. Compared to the existing state of the art self-supervised learning approaches, we empirically showed that CASS trained CNNs, and Transformers across three diverse datasets gained an average of 8.5% with 100% labelled data, 7.3% with 10% labelled data, and 11.5% with 1% labelled data. Notably, one of the test datasets comprised of histopathology slides of an autoimmune disease, a condition with minimal data that has been underrepresented in medical imaging. In addition, our findings revealed that CASS is also more robust than the existing state of the art self-supervised methods. The code is open source and is available on GitHub.
翻译:最近深层学习和计算机愿景的进步减少了自动化医学图像分析的许多障碍,使得算法能够处理无标签图像并改进性能。 具体地说, 变异器提供了图像的全球视角, 即进化神经网络( Convolutional Neal Network, CNNs ) 的内在缺失。 我们在这里展示了十字建筑- 自我监督, 一种利用变异器和CNN的新型自监督学习方法的自监督学习方法。 与目前艺术自监督的学习方法相比, 我们从经验上表明, CASS 培训了CNN, 以及三个不同数据集的变异器平均获得8.5%的标定数据, 7.3%有10%的标定数据,11.5%有1%的标定数据。 值得注意的是, 其中一组测试数据集由自动免疫系统疾病的组织病理学幻灯片组成, 一种条件是医学成像中比例不足的最低限度数据。 此外, 我们的发现, CASS 也比艺术自监督方法的现有状态更可靠。 代码是开放源, 并在 GitHub 上提供。