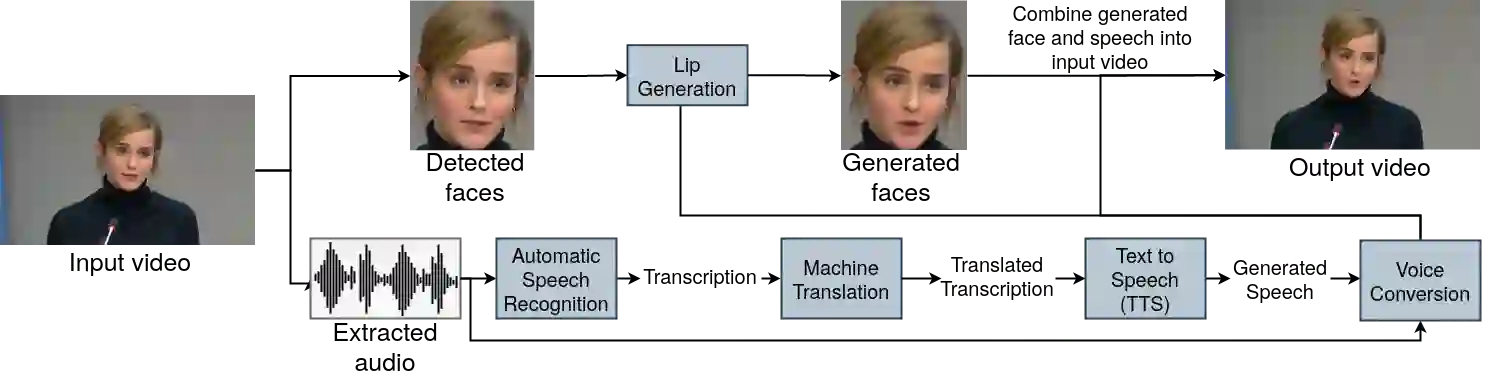
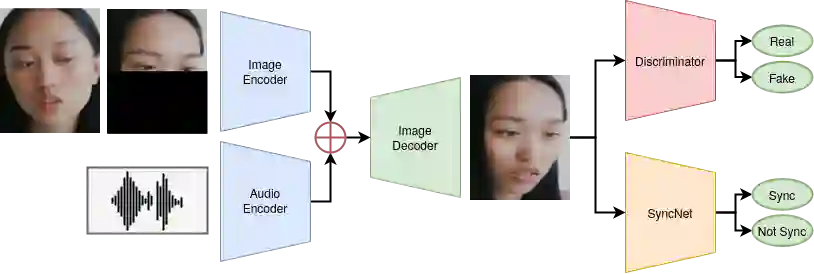
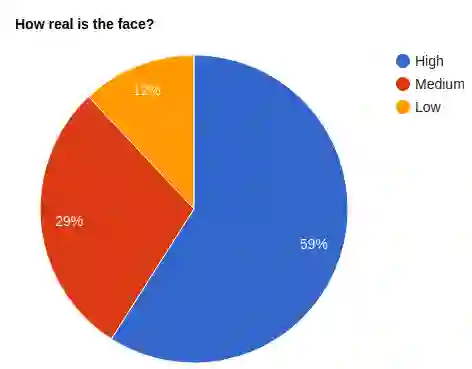
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
翻译:在本文中,我们提出一个神经端对端系统,用于保留声音,对视频进行口对口翻译。这个系统的设计是将多个组件模型结合起来,并制作一个原发言者使用目标语言、与目标演讲口对口的原发言者语言的视频,同时在语言、声音特征、原发言者脸部视频中保持强调,管道从自动语音识别开始,包括重点探测,然后是一个翻译模型。翻译文本由文本对口语言模型合成,该模型重新创建了原句中的原始缩影。由此产生的合成声音随后用声音转换模型绘制回原发言者的原声音。最后,将发言者的嘴唇与已翻译的音频同步同步,同时,一个有条件的基因对抗网络模型生成了与投入面图像和语音转换模型输出有关的经调整的唇动框架。最后,这个系统将生成的原版视频与原版声音合成,以另一种语言进行完整的语音发言视频,而没有实际了解声音转换模式。最后的图像由我们收集的用户嘴唇和原版数据测试数据集,然后我们用一个共同的系统来评估。我们现有的用户数据集,然后是用来评估整个系统,我们现有的系统,然后是用来评估。