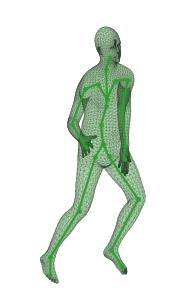
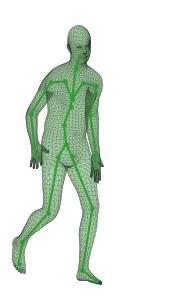
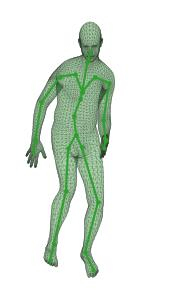
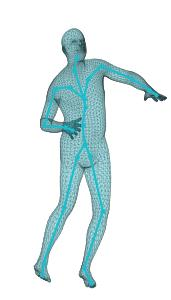
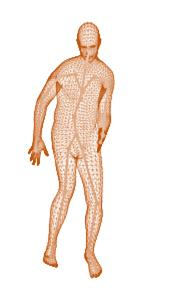
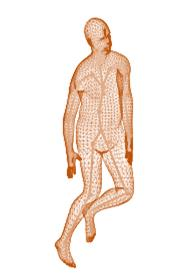
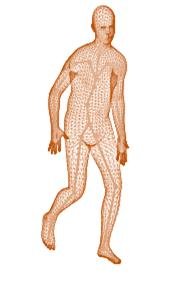
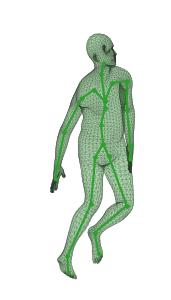
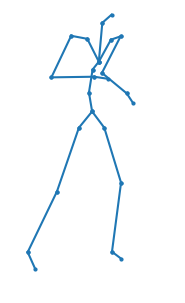
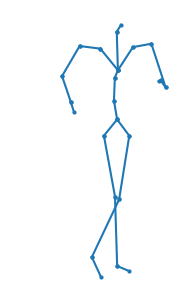
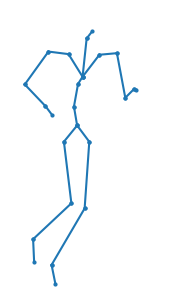
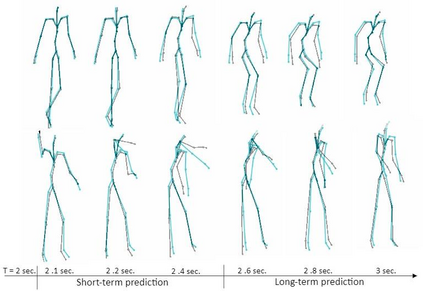
A new method is proposed for human motion predition by learning temporal and spatial dependencies in an end-to-end deep neural network. The joint connectivity is explicitly modeled using a novel autoregressive structured prediction representation based on flow-based generative models. We learn a latent space of complex body poses in consecutive frames which is conditioned on the high-dimensional structure input sequence. To construct each latent variable, the general and local smoothness of the joint positions are considered in a generative process using conditional normalizing flows. As a result, all frame-level and joint-level continuities in the sequence are preserved in the model. This enables us to parameterize the inter-frame and intra-frame relationships and joint connectivity for robust long-term predictions as well as short-term prediction. Our experiments on two challenging benchmark datasets of Human3.6M and AMASS demonstrate that our proposed method is able to effectively model the sequence information for motion prediction and outperform other techniques in 42 of the 48 total experiment scenarios to set a new state-of-the-art.
翻译:通过在端至端深神经网络中学习时间和空间依赖性,为人类运动先导提出了一种新的方法。根据基于流动的基因模型模型,对联合连通作了明确的模型。我们学习了以基于流动的基因模型为基础的新型自动递减结构预测说明;我们学习了以高维结构输入序列为条件的连续框内复杂体的潜在空间。为了构建每个潜在变量,利用有条件的正常化流程,在基因化进程中考虑联合位置的一般和局部的平稳性。因此,在模型中保留了序列中的所有框架级和联合级相联性。这使我们能够对框架间和框架内的关系以及联合连通性进行参数化参数化,以用于稳健的长期预测和短期预测。我们对Human3.6M和AMAS两个具有挑战性的基准数据集的实验表明,我们拟议的方法能够有效地模拟运动预测的序列信息,并在48个总体实验情景中的42个中超越其他技术,以设定新的状态。