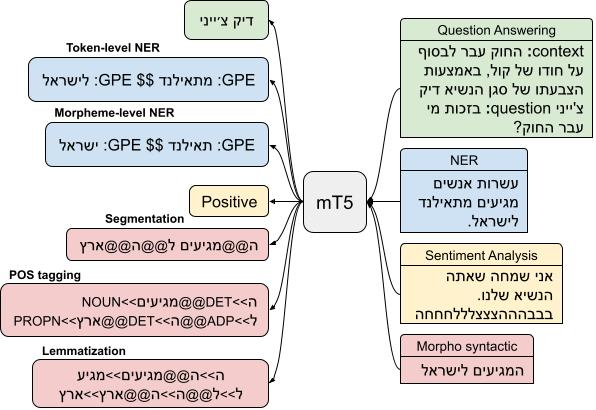
Recent work attributes progress in NLP to large language models (LMs) with increased model size and large quantities of pretraining data. Despite this, current state-of-the-art LMs for Hebrew are both under-parameterized and under-trained compared to LMs in other languages. Additionally, previous work on pretrained Hebrew LMs focused on encoder-only models. While the encoder-only architecture is beneficial for classification tasks, it does not cater well for sub-word prediction tasks, such as Named Entity Recognition, when considering the morphologically rich nature of Hebrew. In this paper we argue that sequence-to-sequence generative architectures are more suitable for LLMs in the case of morphologically rich languages (MRLs) such as Hebrew. We demonstrate that by casting tasks in the Hebrew NLP pipeline as text-to-text tasks, we can leverage powerful multilingual, pretrained sequence-to-sequence models as mT5, eliminating the need for a specialized, morpheme-based, separately fine-tuned decoder. Using this approach, our experiments show substantial improvements over previously published results on existing Hebrew NLP benchmarks. These results suggest that multilingual sequence-to-sequence models present a promising building block for NLP for MRLs.
翻译:尽管如此,目前希伯来语最先进的LMS相对于其他语言最丰富的LMS而言,其程度仍然不够和训练不足。此外,以前关于预先训练的希伯来语LMS的工作侧重于只使用编码器的模型。虽然只使用编码器的架构有利于分类任务,但是在考虑希伯来语的形态丰富性质时,它不能很好地满足亚字预测任务,如命名实体识别。在本文中,我们认为,相对于希伯来语等具有形态丰富语言的LMS来说,顺序到序列的基因结构更适合LMS。我们通过在希伯来语NLP管道中将任务作为文本到文本的任务进行选择,我们可以通过强大的多语种、事先训练的序列到后导模型,如MT5,消除了专门、基于灰色的、分别调整的脱coder的需要。我们用这一方法实验显示,在以原有的NPLML系列制作成果方面,比以前公布的ML系列要大得多。