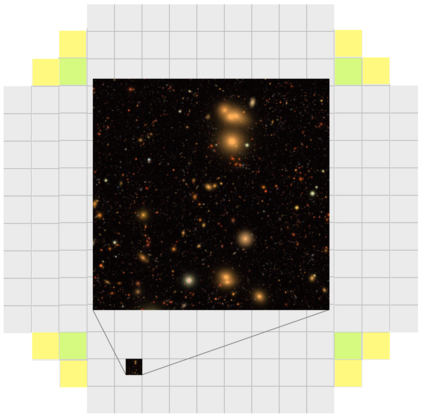
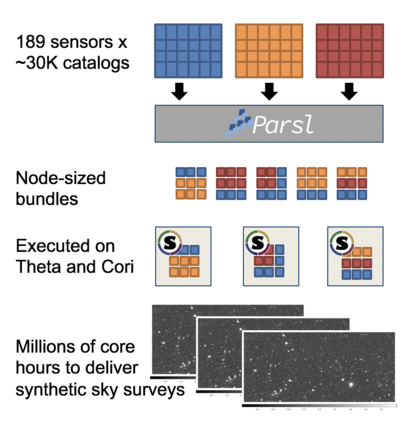
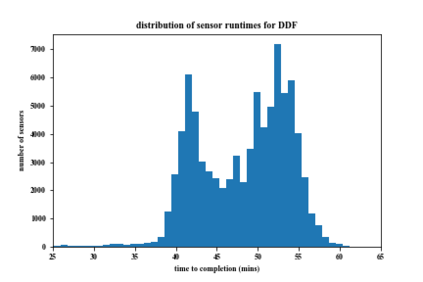
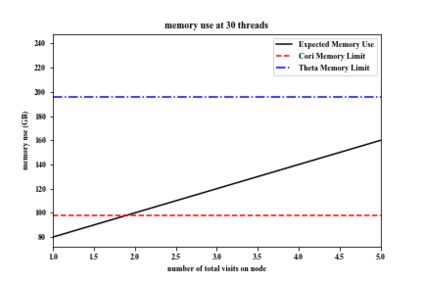
The Vera C. Rubin Observatory Legacy Survey of Space and Time (LSST) will soon carry out an unprecedented wide, fast, and deep survey of the sky in multiple optical bands. The data from LSST will open up a new discovery space in astronomy and cosmology, simultaneously providing clues toward addressing burning issues of the day, such as the origin of dark energy and and the nature of dark matter, while at the same time yielding data that will, in turn, pose fresh new questions. To prepare for the imminent arrival of this remarkable data set, it is crucial that the associated scientific communities be able to develop the software needed to analyze it. Computational power now available allows us to generate synthetic data sets that can be used as a realistic training ground for such an effort. This effort raises its own challenges -- the need to generate very large simulations of the night sky, scaling up simulation campaigns to large numbers of compute nodes across multiple computing centers with different architectures, and optimizing the complex workload around memory requirements and widely varying wall clock times. We describe here a large-scale workflow that melds together Python code to steer the workflow, Parsl to manage the large-scale distributed execution of workflow components, and containers to carry out the image simulation campaign across multiple sites. Taking advantage of these tools, we developed an extreme-scale computational framework and used it to simulate five years of observations for 300 square degrees of sky area. We describe our experiences and lessons learned in developing this workflow capability, and highlight how the scalability and portability of our approach enabled us to efficiently execute it on up to 4000 compute nodes on two supercomputers.
翻译:Vera C. Rubin天文台空间和时间遗产调查(LSST)不久将进行前所未有的广泛、快速和深入的多光谱波段天空调查。LSST的数据将打开天文学和宇宙学的新发现空间,同时提供解决当日燃烧问题的线索,例如暗能量的来源和暗物质的性质,同时生成大量数据,从而产生新的新问题。为即将到来的这一了不起的数据集做准备,40个相关科学界必须能够开发分析它所需的软件。目前可用的计算能力将使我们能够生成合成数据集,这些数据集将用作现实的天文学和宇宙学培训场。这项努力提出了自己的挑战 -- -- 需要生成非常大规模的夜空模拟,将模拟运动扩大到具有不同结构的多个计算机中心之间的大量编译节点,并优化围绕记忆方法和广泛不同的墙钟时间的复杂工作量。我们在这里描述一个大型工作流程,在Pyson观测中与Pyon观测码一起,将这一系统生成的合成数据集,用于在5年的模拟运动中进行大规模计算。我们如何在运行这些模拟运动的轨道上,在运行过程中,将运用这些模拟工具的大规模地平流流流流流中,管理我们用来管理这些系统工具。