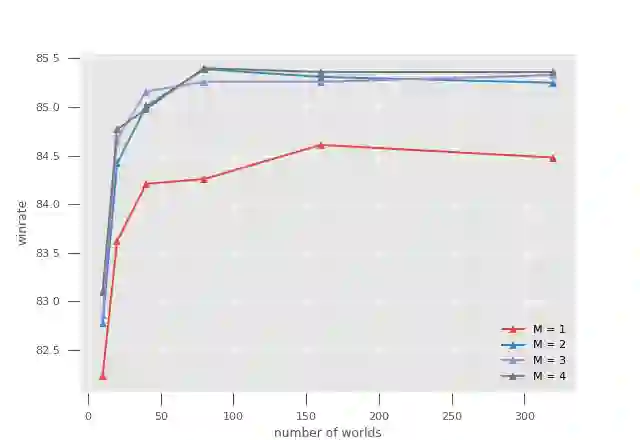
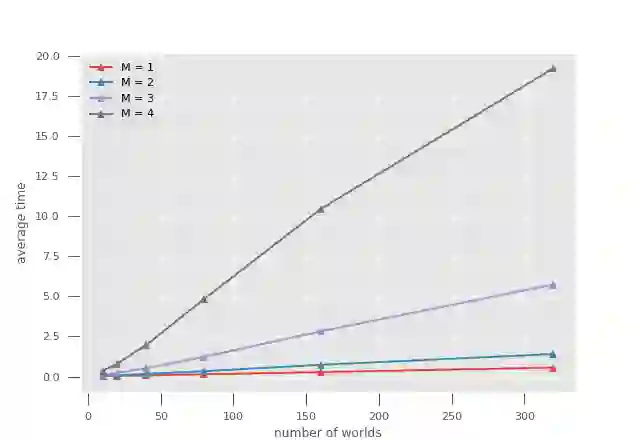
$\alpha\mu$ is a search algorithm which repairs two defaults of Perfect Information Monte Carlo search: strategy fusion and non locality. In this paper we optimize $\alpha\mu$ for the game of Bridge, avoiding useless computations. The proposed optimizations are general and apply to other imperfect information turn-based games. We define multiple optimizations involving Pareto fronts, and show that these optimizations speed up the search. Some of these optimizations are cuts that stop the search at a node, while others keep track of which possible worlds have become redundant, avoiding unnecessary, costly evaluations. We also measure the benefits of parallelizing the double dummy searches at the leaves of the $\alpha\mu$ search tree.
翻译:$\ alpha\ mu$ 是一种搜索算法,它修复了蒙特卡洛完美信息搜索的两个默认值: 战略融合和非地点。 在本文中, 我们优化了用于桥牌游戏的 $\ alpha\ mu$, 避免了无用的计算。 提议的优化是一般性的, 适用于其他不完善的信息翻转游戏 。 我们定义了涉及 Pareto 的多重优化, 并显示这些优化加快了搜索速度 。 有些优化是削减, 停止在节点搜索, 而另一些优化则跟踪了哪些可能的世界已经变得多余, 避免了不必要的、 昂贵的评估 。 我们还测量了在$\ alpha\ mu$ 搜索树叶上平行进行双假搜索的好处 。