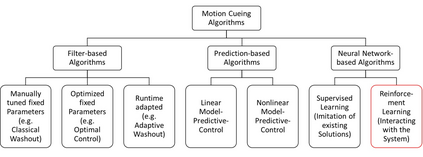
In motion simulation, motion cueing algorithms are used for the trajectory planning of the motion simulator platform, where workspace limitations prevent direct reproduction of reference trajectories. Strategies such as motion washout, which return the platform to its center, are crucial in these settings. For serial robotic MSPs with highly nonlinear workspaces, it is essential to maximize the efficient utilization of the MSPs kinematic and dynamic capabilities. Traditional approaches, including classical washout filtering and linear model predictive control, fail to consider platform-specific, nonlinear properties, while nonlinear model predictive control, though comprehensive, imposes high computational demands that hinder real-time, pilot-in-the-loop application without further simplification. To overcome these limitations, we introduce a novel approach using deep reinforcement learning for motion cueing, demonstrated here for the first time in a 6-degree-of-freedom setting with full consideration of the MSPs kinematic nonlinearities. Previous work by the authors successfully demonstrated the application of DRL to a simplified 2-DOF setup, which did not consider kinematic or dynamic constraints. This approach has been extended to all 6 DOF by incorporating a complete kinematic model of the MSP into the algorithm, a crucial step for enabling its application on a real motion simulator. The training of the DRL-MCA is based on Proximal Policy Optimization in an actor-critic implementation combined with an automated hyperparameter optimization. After detailing the necessary training framework and the algorithm itself, we provide a comprehensive validation, demonstrating that the DRL MCA achieves competitive performance against established algorithms. Moreover, it generates feasible trajectories by respecting all system constraints and meets all real-time requirements with low...
翻译:暂无翻译