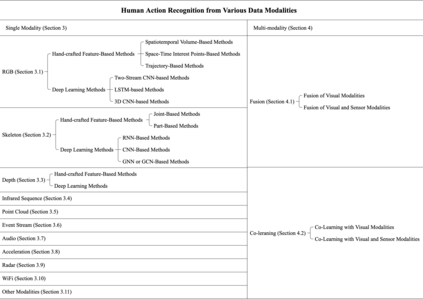
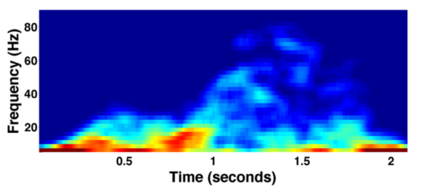
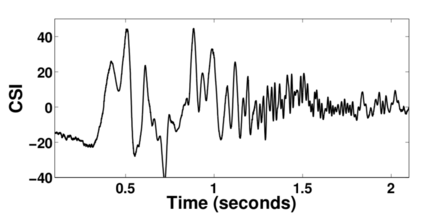
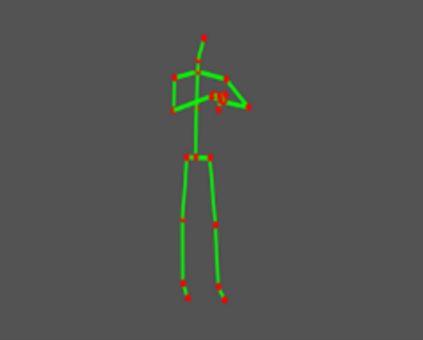
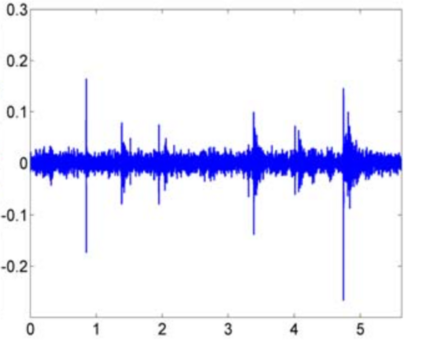
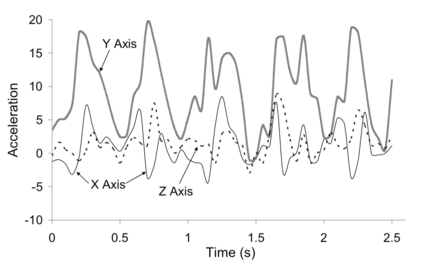
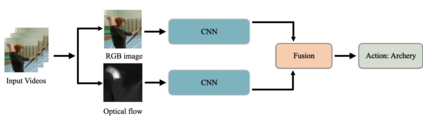
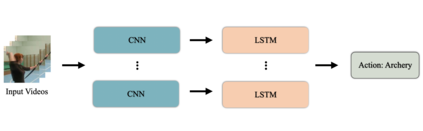
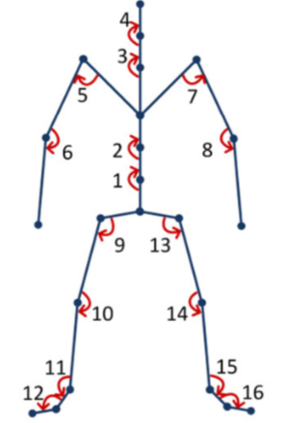
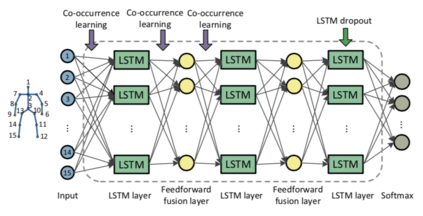
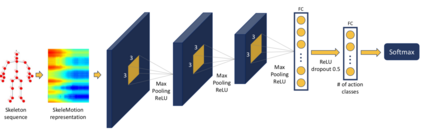
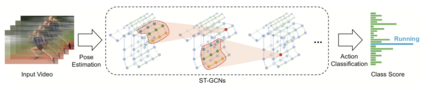
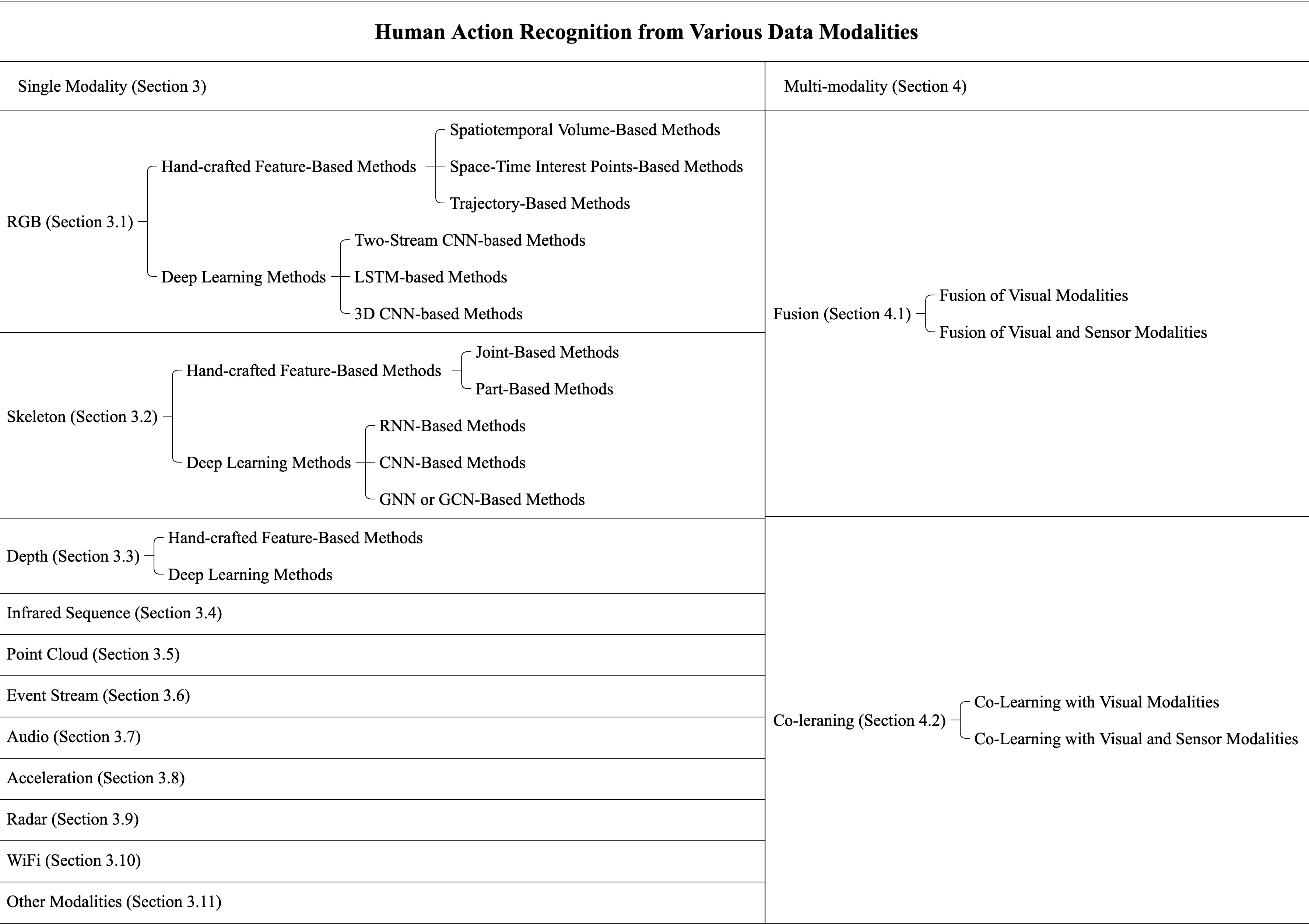
Human Action Recognition (HAR), aiming to understand human behaviors and then assign category labels, has a wide range of applications, and thus has been attracting increasing attention in the field of computer vision. Generally, human actions can be represented using various data modalities, such as RGB, skeleton, depth, infrared sequence, point cloud, event stream, audio, acceleration, radar, and WiFi, etc., which encode different sources of useful yet distinct information and have various advantages and application scenarios. Consequently, lots of existing works have attempted to investigate different types of approaches for HAR using various modalities. In this paper, we give a comprehensive survey for HAR from the perspective of the input data modalities. Specifically, we review both the hand-crafted feature-based and deep learning-based methods for single data modalities, and also review the methods based on multiple modalities, including the fusion-based frameworks and the co-learning-based approaches. The current benchmark datasets for HAR are also introduced. Finally, we discuss some potentially important research directions in this area.
翻译:人类行动认知(HAR)旨在了解人类行为,然后分配类别标签,具有广泛的应用,因此在计算机愿景领域日益引起人们的关注。一般而言,人类行动可以使用各种数据模式,如RGB、骨架、深度、红外序列、点云、事件流、音频、加速、雷达和WiFi等,这些模式汇集了不同来源的有用但又独特的信息,并具有各种优势和应用设想。因此,许多现有工作都试图以不同方式调查HAR的不同类型方法。在本文件中,我们从输入数据模式的角度对HAR进行了全面调查。具体地说,我们审查了手制的单一数据模式基于地貌和深层次学习的方法,还审查了基于多种模式的方法,包括基于聚合的框架和基于共同学习的方法。还介绍了目前HAR的基准数据集。最后,我们讨论了这一领域一些可能重要的研究方向。