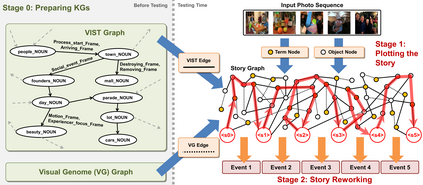
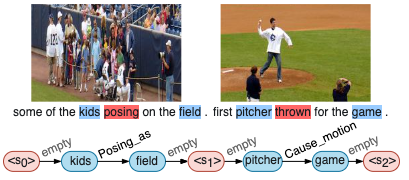
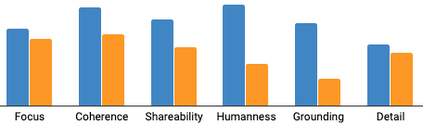
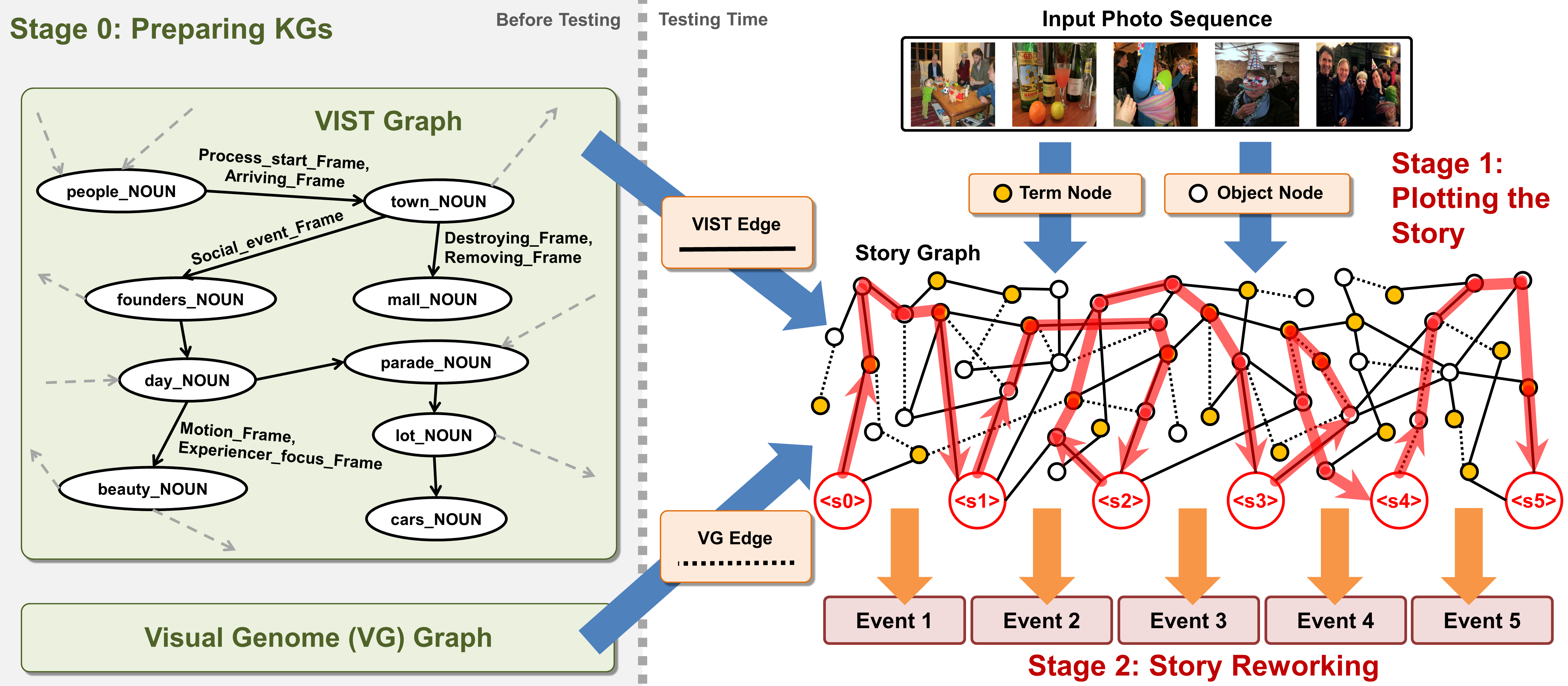
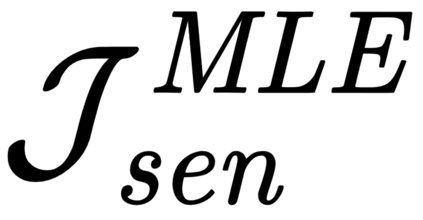Writing a coherent and engaging story is not easy. Creative writers use their knowledge and worldview to put disjointed elements together to form a coherent storyline, and work and rework iteratively toward perfection. Automated visual storytelling (VIST) models, however, make poor use of external knowledge and iterative generation when attempting to create stories. This paper introduces PR-VIST, a framework that represents the input image sequence as a story graph in which it finds the best path to form a storyline. PR-VIST then takes this path and learns to generate the final story via an iterative training process. This framework produces stories that are superior in terms of diversity, coherence, and humanness, per both automatic and human evaluations. An ablation study shows that both plotting and reworking contribute to the model's superiority.
翻译:写一个连贯而活泼的故事并非易事。 创意作家利用他们的知识和世界观将互不关联的元素放在一起,形成一个连贯的故事线,并反复地工作和重新工作到完美。 然而,自动视觉故事讲述模型在试图创建故事时,对外部知识和迭代生成作用很差。 本文介绍了PR-VIST这个框架,它代表输入图像序列,作为它找到形成故事线的最佳途径的故事图。 PR-VIST随后走这条道路,学习通过迭代培训过程生成最后的故事。 这个框架生成了在多样性、一致性和人性方面都处于领先地位的故事,既包括自动评价,也包括人类评价。 一份赞美研究显示,规划和重新工作都有助于模型的优越性。