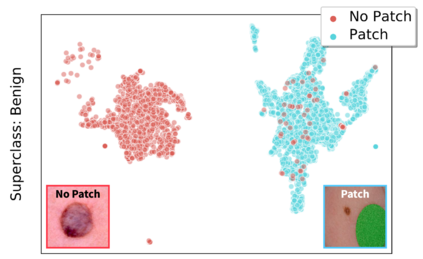
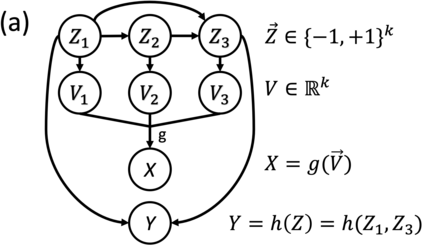
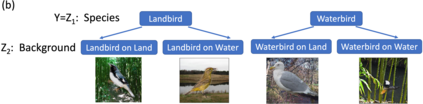
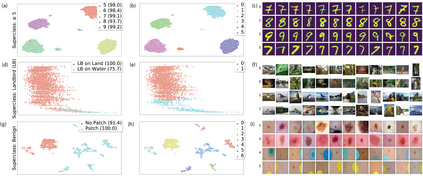
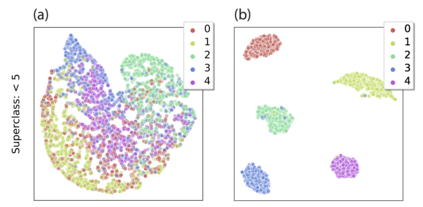
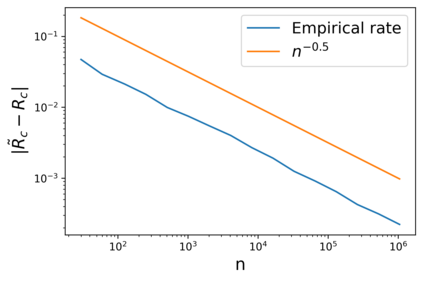
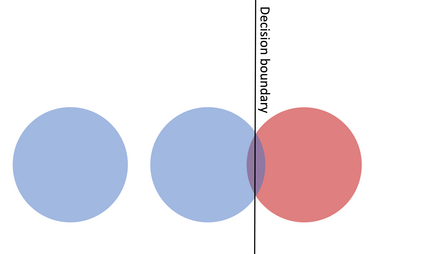
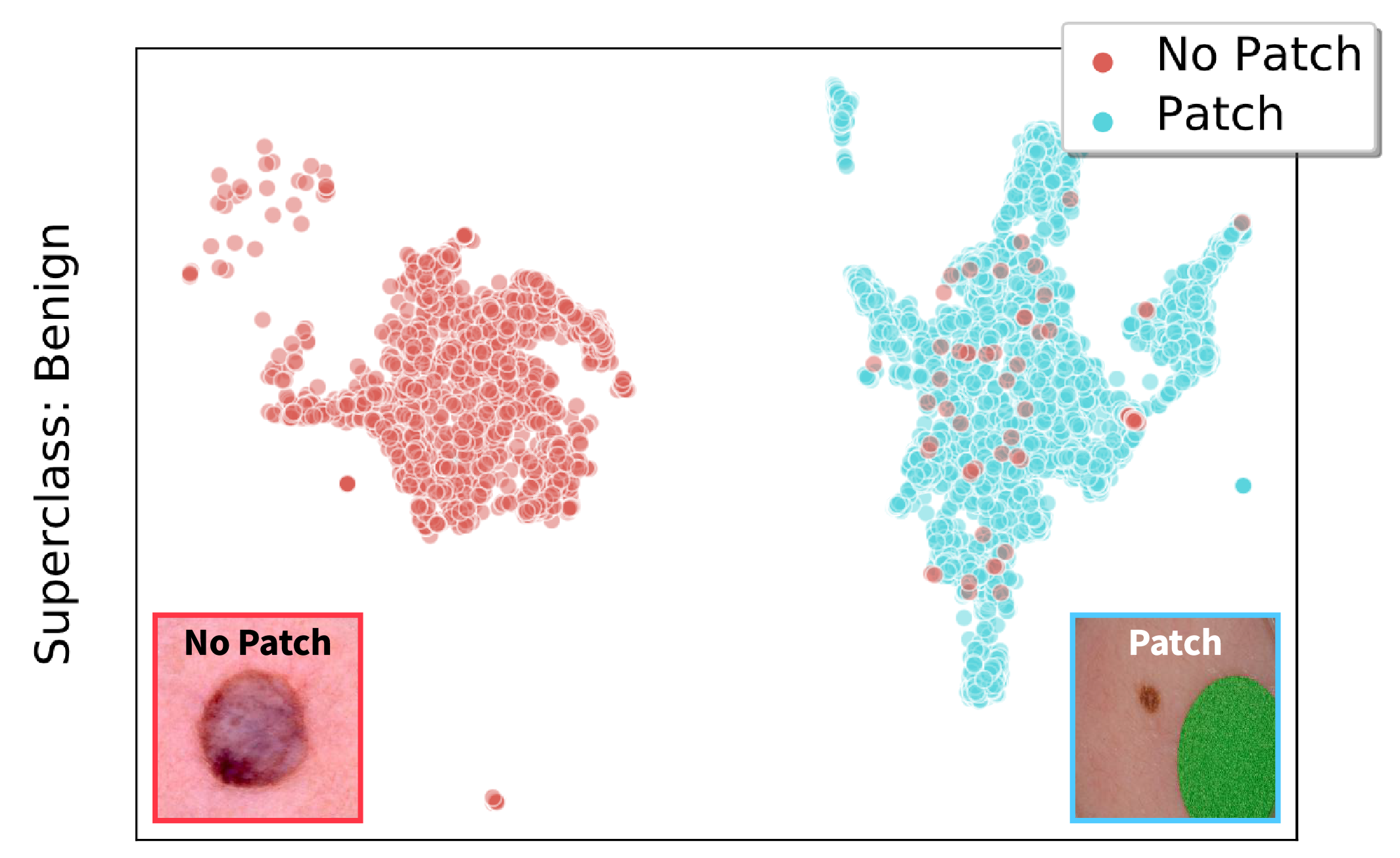
In real-world classification tasks, each class often comprises multiple finer-grained "subclasses." As the subclass labels are frequently unavailable, models trained using only the coarser-grained class labels often exhibit highly variable performance across different subclasses. This phenomenon, known as hidden stratification, has important consequences for models deployed in safety-critical applications such as medicine. We propose GEORGE, a method to both measure and mitigate hidden stratification even when subclass labels are unknown. We first observe that unlabeled subclasses are often separable in the feature space of deep models, and exploit this fact to estimate subclass labels for the training data via clustering techniques. We then use these approximate subclass labels as a form of noisy supervision in a distributionally robust optimization objective. We theoretically characterize the performance of GEORGE in terms of the worst-case generalization error across any subclass. We empirically validate GEORGE on a mix of real-world and benchmark image classification datasets, and show that our approach boosts worst-case subclass accuracy by up to 22 percentage points compared to standard training techniques, without requiring any information about the subclasses.
翻译:在现实世界的分类任务中,每类通常包括多个细细的“子类”分类。由于子类标签经常得不到,只使用粗粗的分类标签而培训的模型往往在不同小类中表现出高度差异性能。这种现象被称为隐藏的分层,对安全关键应用(如医学)中的模型具有重要影响。我们提议GEGROGE,这是测量和减轻隐藏分层的方法,即使分级标签未知。我们首先观察到,未标记的子类往往在深层模型的特征空间中可以分离,并利用这一事实来估计培训数据的子类标签。我们随后将这些近似小类标签作为在分布上非常强的优化目标中进行吵闹监管的一种形式。我们理论上将GEGORGE的性能定性为任何子类最差的通用错误。我们从经验上验证GEGERGE在现实世界和基准图像分类数据集的组合上,并显示我们的方法比标准培训技术提高了最差的子类的精确度,最高为22个百分点,不需要任何信息。