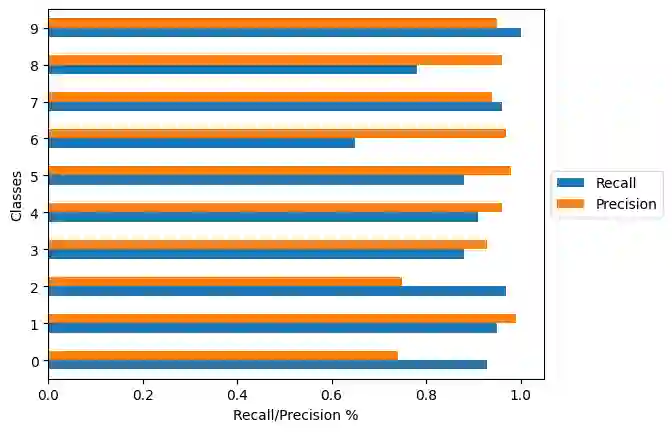
Semi-supervised learning (SSL) has made significant strides in the field of remote sensing. Finding a large number of labeled datasets for SSL methods is uncommon, and manually labeling datasets is expensive and time-consuming. Furthermore, accurately identifying remote sensing satellite images is more complicated than it is for conventional images. Class-imbalanced datasets are another prevalent phenomenon, and models trained on these become biased towards the majority classes. This becomes a critical issue with an SSL model's subpar performance. We aim to address the issue of labeling unlabeled data and also solve the model bias problem due to imbalanced datasets while achieving better accuracy. To accomplish this, we create "artificial" labels and train a model to have reasonable accuracy. We iteratively redistribute the classes through resampling using a distribution alignment technique. We use a variety of class imbalanced satellite image datasets: EuroSAT, UCM, and WHU-RS19. On UCM balanced dataset, our method outperforms previous methods MSMatch and FixMatch by 1.21% and 0.6%, respectively. For imbalanced EuroSAT, our method outperforms MSMatch and FixMatch by 1.08% and 1%, respectively. Our approach significantly lessens the requirement for labeled data, consistently outperforms alternative approaches, and resolves the issue of model bias caused by class imbalance in datasets.
翻译:半监督的学习(SSL)在遥感领域取得了长足的进步。为 SSL 方法找到大量贴标签的数据集并不常见,人工标签的数据集成本昂贵,耗费时间。此外,精确地识别遥感卫星图像比常规图像复杂得多。类平衡数据集是另一个普遍现象,为此培训的模型偏向多数类。这成为了SSL模型子级性能的关键问题。我们的目标是解决标签未贴标签的数据问题,并解决由于数据集不平衡而导致的模型偏差问题。要做到这一点,我们创建“人工”标签并训练一个模型以达到合理的准确性。我们通过使用分布校正校准技术重新标出各个类。我们使用各种类不平衡的卫星图像数据集发行:EuroSAT、UCMM和WHU-RS19模型。在 UCM 平衡数据集方面,我们的方法比以往的MSMatch和CixMatch方法高出1.21%和0.6%。要做到这一点,我们创建“人造型”标签的模型分别导致Sixd 和Ms IM 的系统数据配置方法明显减少。