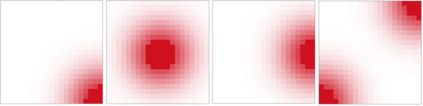
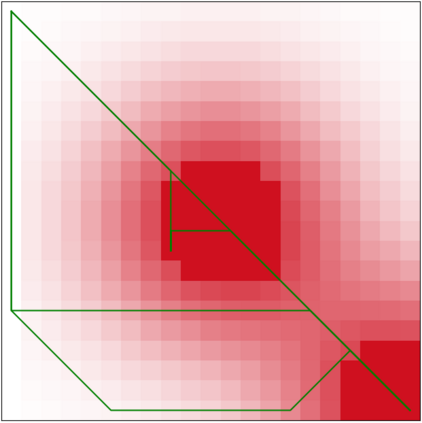
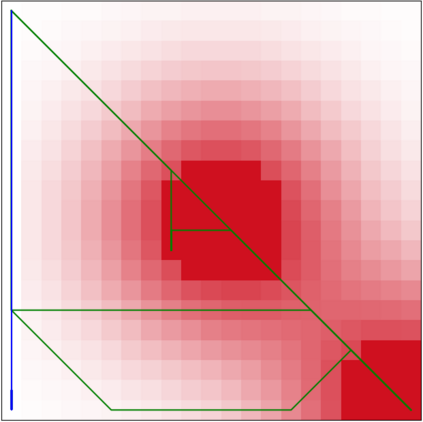
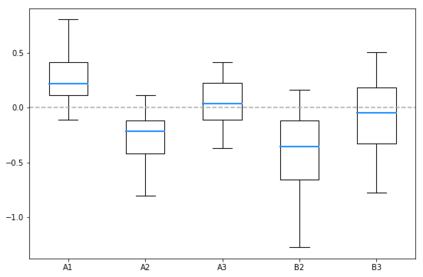
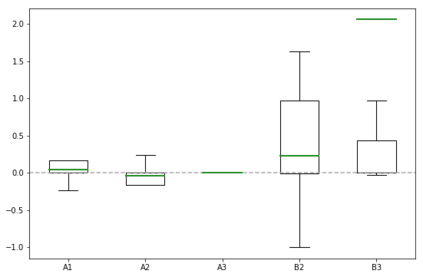
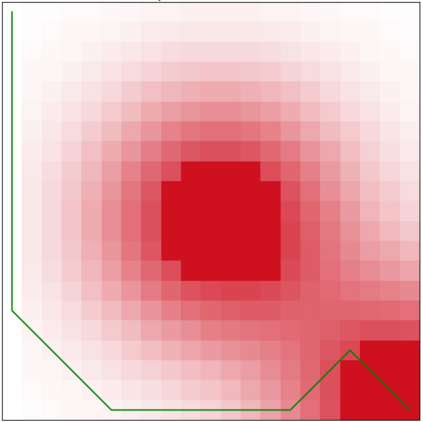
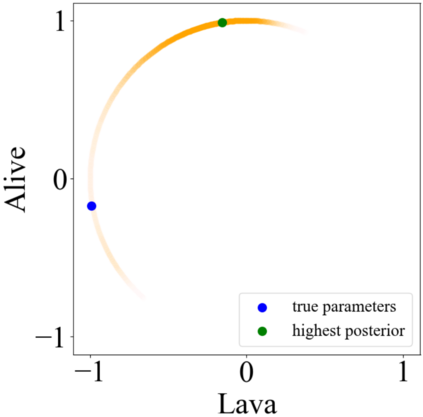
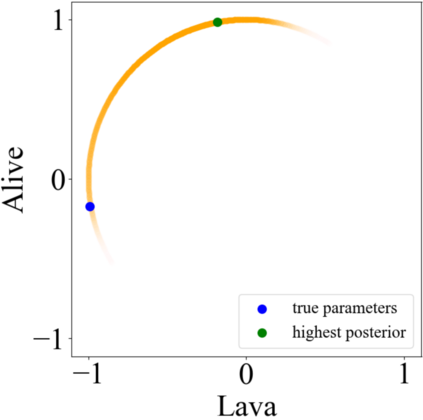
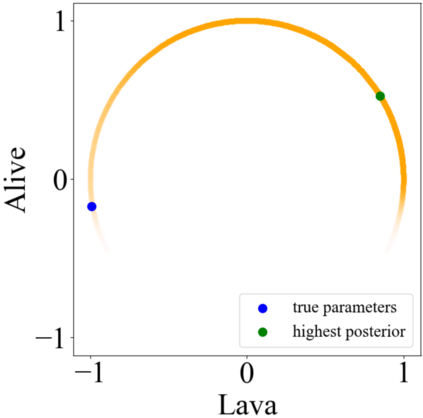
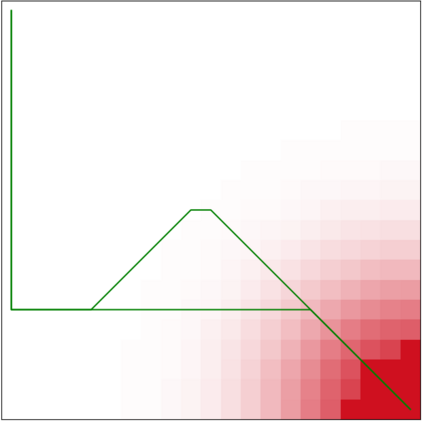
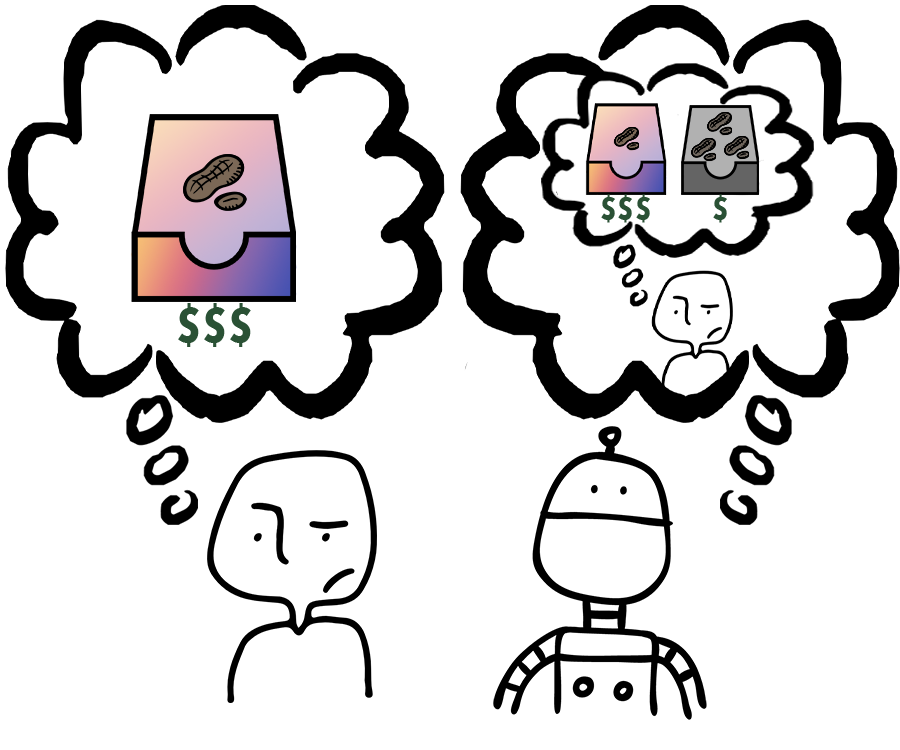Specifying reward functions for robots that operate in environments without a natural reward signal can be challenging, and incorrectly specified rewards can incentivise degenerate or dangerous behavior. A promising alternative to manually specifying reward functions is to enable robots to infer them from human feedback, like demonstrations or corrections. To interpret this feedback, robots treat as approximately optimal a choice the person makes from a choice set, like the set of possible trajectories they could have demonstrated or possible corrections they could have made. In this work, we introduce the idea that the choice set itself might be difficult to specify, and analyze choice set misspecification: what happens as the robot makes incorrect assumptions about the set of choices from which the human selects their feedback. We propose a classification of different kinds of choice set misspecification, and show that these different classes lead to meaningful differences in the inferred reward and resulting performance. While we would normally expect misspecification to hurt, we find that certain kinds of misspecification are neither helpful nor harmful (in expectation). However, in other situations, misspecification can be extremely harmful, leading the robot to believe the opposite of what it should believe. We hope our results will allow for better prediction and response to the effects of misspecification in real-world reward inference.
翻译:指定在没有自然奖赏信号的环境中运作的机器人的奖赏功能可能具有挑战性,而错误指定的奖赏可能会激励堕落或危险的行为。人工指定奖赏功能的一个有希望的替代办法是让机器人能够从人类的反馈中推断出这些奖赏,例如演示或校正。为了解释这种反馈,机器人将一个人从一组选择中作出的选择视为近乎最佳的选择,例如他们本可以展示的一套可能的轨迹或他们可能作出的可能纠正。在这项工作中,我们提出这样一种想法,即选择集本身可能难以具体指定,并分析选择的定点错误:当机器人对一组选择作出错误的假设,而人类从中选择他们的反馈时会发生什么情况。我们建议对不同种类的选择进行分类,并表明这些不同的类别会导致推断奖励和导致业绩的有意义的差异。我们通常会期望有伤害性,但我们发现某些种类的定点既不有用,也有害(期望 ) 。然而, 在其他情况下,错误的定点可能极为有害,导致机器人相信它所应该相信的反面的精确性。 我们希望,我们的预测结果将有利于世界的预测和结果。