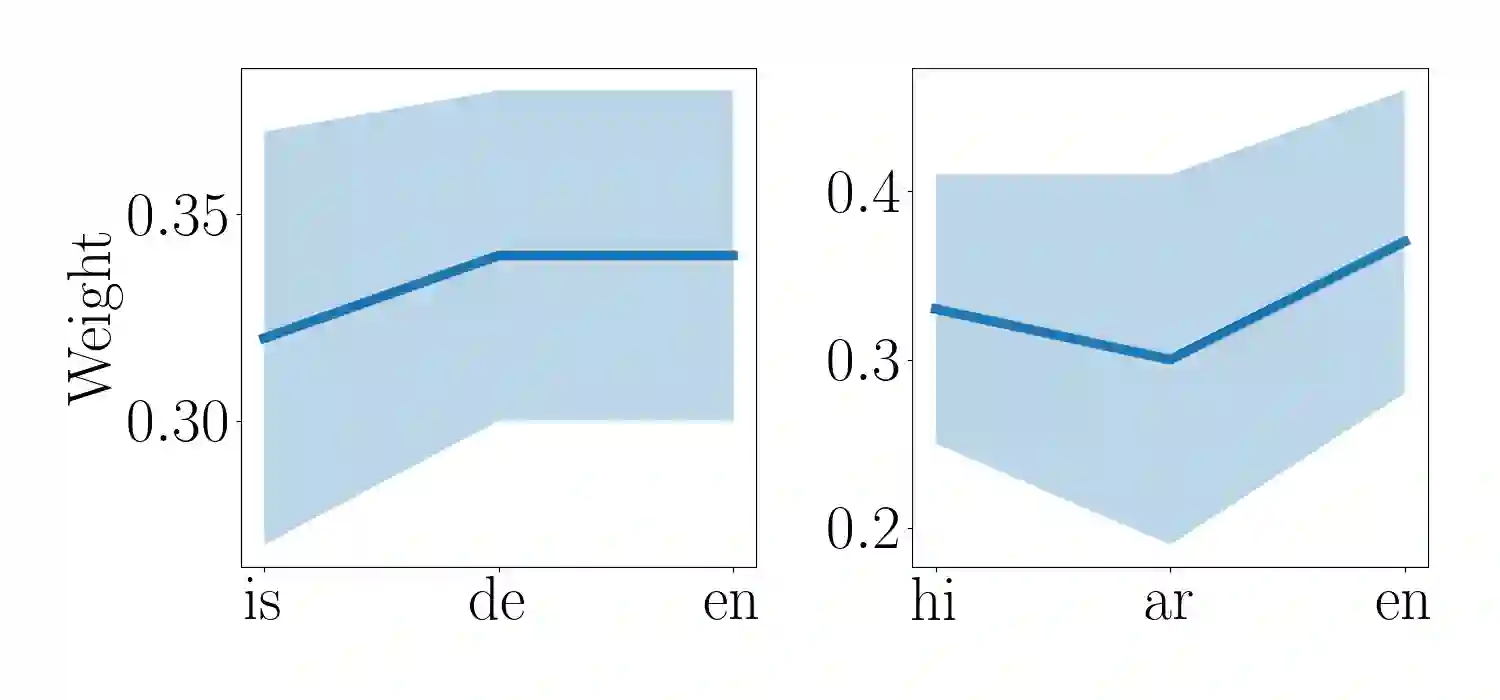
Adapters are light-weight modules that allow parameter-efficient fine-tuning of pretrained models. Specialized language and task adapters have recently been proposed to facilitate cross-lingual transfer of multilingual pretrained models (Pfeiffer et al., 2020b). However, this approach requires training a separate language adapter for every language one wishes to support, which can be impractical for languages with limited data. An intuitive solution is to use a related language adapter for the new language variety, but we observe that this solution can lead to sub-optimal performance. In this paper, we aim to improve the robustness of language adapters to uncovered languages without training new adapters. We find that ensembling multiple existing language adapters makes the fine-tuned model significantly more robust to other language varieties not included in these adapters. Building upon this observation, we propose Entropy Minimized Ensemble of Adapters (EMEA), a method that optimizes the ensemble weights of the pretrained language adapters for each test sentence by minimizing the entropy of its predictions. Experiments on three diverse groups of language varieties show that our method leads to significant improvements on both named entity recognition and part-of-speech tagging across all languages.
翻译:适应器是能够对经过事先培训的模型进行参数高效微调的轻量模块。最近提出了专门语言和任务适应器的建议,以便利多语言的跨语言转让多语言先行模式(Pfeiffer等人,2020年b)。然而,这一方法要求为所支持的每一种语言培训一个单独的语言适应器,这对于数据有限的语言来说可能不切实际。一个直观的解决方案是使用一种相关的语言适应器来适应新语言的多样性,但我们认为,这一解决方案可以导致次优的性能。在本文中,我们的目标是提高语言适应器对未发现的语言的稳健性,而不培训新的适应器。我们发现,组合多种现有语言适应器使经过精细调整的模型对未包括在这些适应器中的其他语言品种更加强大。基于这一观察,我们建议对适应器的最小化集合器(Entropy 最小化器)采用一种方法,通过最大限度地减少其预测的英式,优化每个测试句中未受过训练的语言适应器的共重度。对三种语言的比重。对三种不同的语言品种的实验显示我们的方法在两个名称上都有显著的标记。