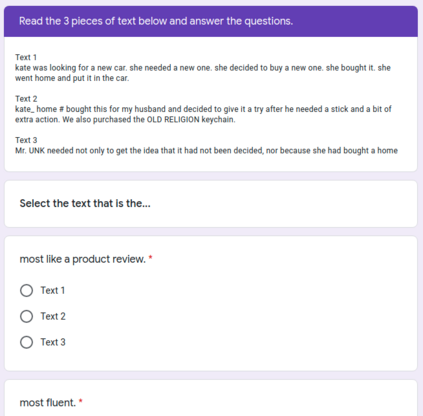
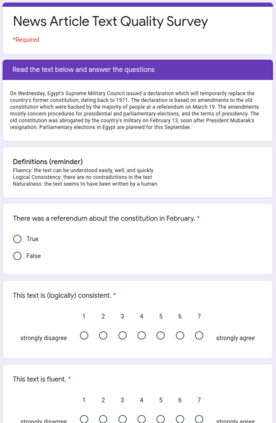
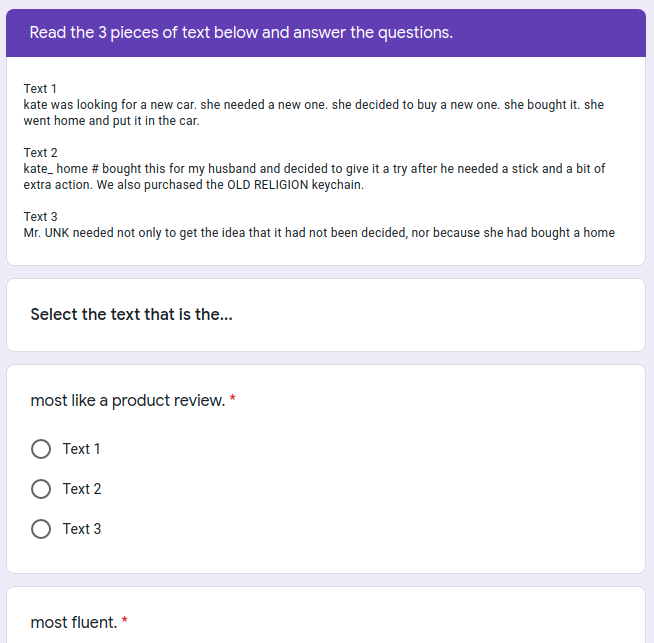
Large pre-trained language models have repeatedly shown their ability to produce fluent text. Yet even when starting from a prompt, generation can continue in many plausible directions. Current decoding methods with the goal of controlling generation, e.g., to ensure specific words are included, either require additional models or fine-tuning, or work poorly when the task at hand is semantically unconstrained, e.g., story generation. In this work, we present a plug-and-play decoding method for controlled language generation that is so simple and intuitive, it can be described in a single sentence: given a topic or keyword, we add a shift to the probability distribution over our vocabulary towards semantically similar words. We show how annealing this distribution can be used to impose hard constraints on language generation, something no other plug-and-play method is currently able to do with SOTA language generators. Despite the simplicity of this approach, we see it works incredibly well in practice: decoding from GPT-2 leads to diverse and fluent sentences while guaranteeing the appearance of given guide words. We perform two user studies, revealing that (1) our method outperforms competing methods in human evaluations; and (2) forcing the guide words to appear in the generated text has no impact on the fluency of the generated text.
翻译:受过训练的大型语言模型反复展示了它们制作流畅文本的能力。 然而,即使从一个快速的开始开始, 一代也可以继续在许多貌似合理的方向中进行。 当前解码方法的目的是控制生成, 例如,确保包含具体的单词, 需要额外的模型或微调, 或者当手头的任务在语义上不受约束时工作不力, 比如说故事生成。 在这项工作中, 我们为受控的语言生成提供了一个插接和播放解码方法, 这个方法非常简单和直观, 它可以在单句中描述: 给一个主题或关键字, 我们增加一种改变, 将词汇的概率分布转换到语义相似的单词。 我们展示了如何用安眠方法来对语言生成施加严格的限制, 而目前没有其它的插和播放方法能够对 SOTA 语言生成者进行操作。 尽管这个方法简单, 我们发现它在实践中非常有效: 从 GPT-2 解解解解码导致多样化和流利的句, 同时保证给定的词的外观的外观。 我们进行了两种用户研究, 显示我们生成的文字的文本的顺序似乎不同的方法。