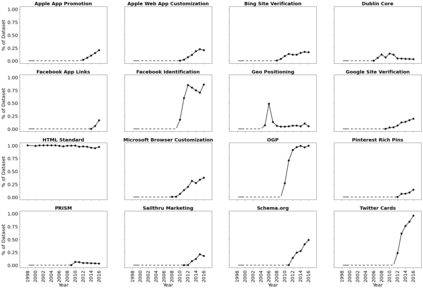
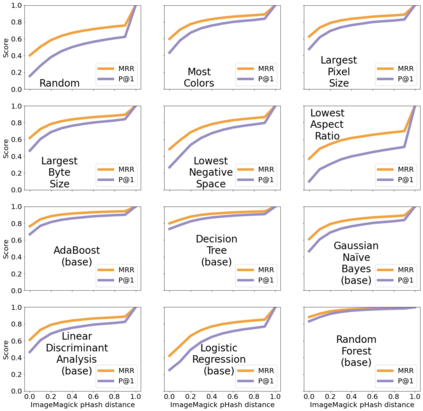
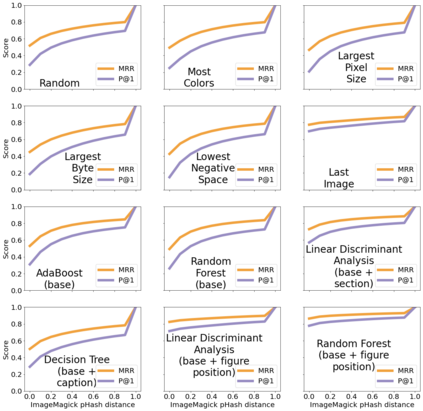
To allow previewing a web page, social media platforms have developed social cards: visualizations consisting of vital information about the underlying resource. At a minimum, social cards often include features such as the web resource's title, text summary, striking image, and domain name. News and scholarly articles on the web are frequently subject to social card creation when being shared on social media. However, we noticed that not all web resources offer sufficient metadata elements to enable appealing social cards. For example, the COVID-19 emergency has made it clear that scholarly articles, in particular, are at an aesthetic disadvantage in social media platforms when compared to their often more flashy disinformation rivals. Also, social cards are often not generated correctly for archived web resources, including pages that lack or predate standards for specifying striking images. With these observations, we are motivated to quantify the levels of inclusion of required metadata in web resources, its evolution over time for archived resources, and create and evaluate an algorithm to automatically select a striking image for social cards. We find that more than 40% of archived news articles sampled from the NEWSROOM dataset and 22% of scholarly articles sampled from the PubMed Central dataset fail to supply striking images. We demonstrate that we can automatically predict the striking image with a Precision@1 of 0.83 for news articles from NEWSROOM and 0.78 for scholarly articles from the open access journal PLOS ONE.
翻译:为预览网页,社交媒体平台开发了社交卡片:视觉化由关于原始资源的重要信息构成。至少,社交卡片通常包括网络资源标题、文本摘要、冲击图像和域名等特征。网络上的新闻和学术文章在社交媒体上共享时经常受到社会卡创建的制约。然而,我们注意到并非所有网络资源都提供了足够的元数据元素,以吸引社交卡。例如,COVID-19紧急事件清楚地表明,在社交媒体平台上,学术文章尤其处于美学劣势,与通常更闪亮的错失信息对手相比。此外,社交卡往往不正确生成存档的网络资源,包括缺乏或提前指定惊人图像的标准的页面。有了这些观察,我们有志于量化将所需元数据纳入网络资源的程度,并随着存档资源的时间演变,并创建和评估了自动选择社会卡片公开图像的算法。我们发现,40 %以上的存档新闻文章样本来自UNISROOM数据集,22 %的社交卡卡片期刊用于存档的PUMERMSERMS 图像,我们无法从POMSERMSIM1号中自动地展示了我们浏览的中央图像。