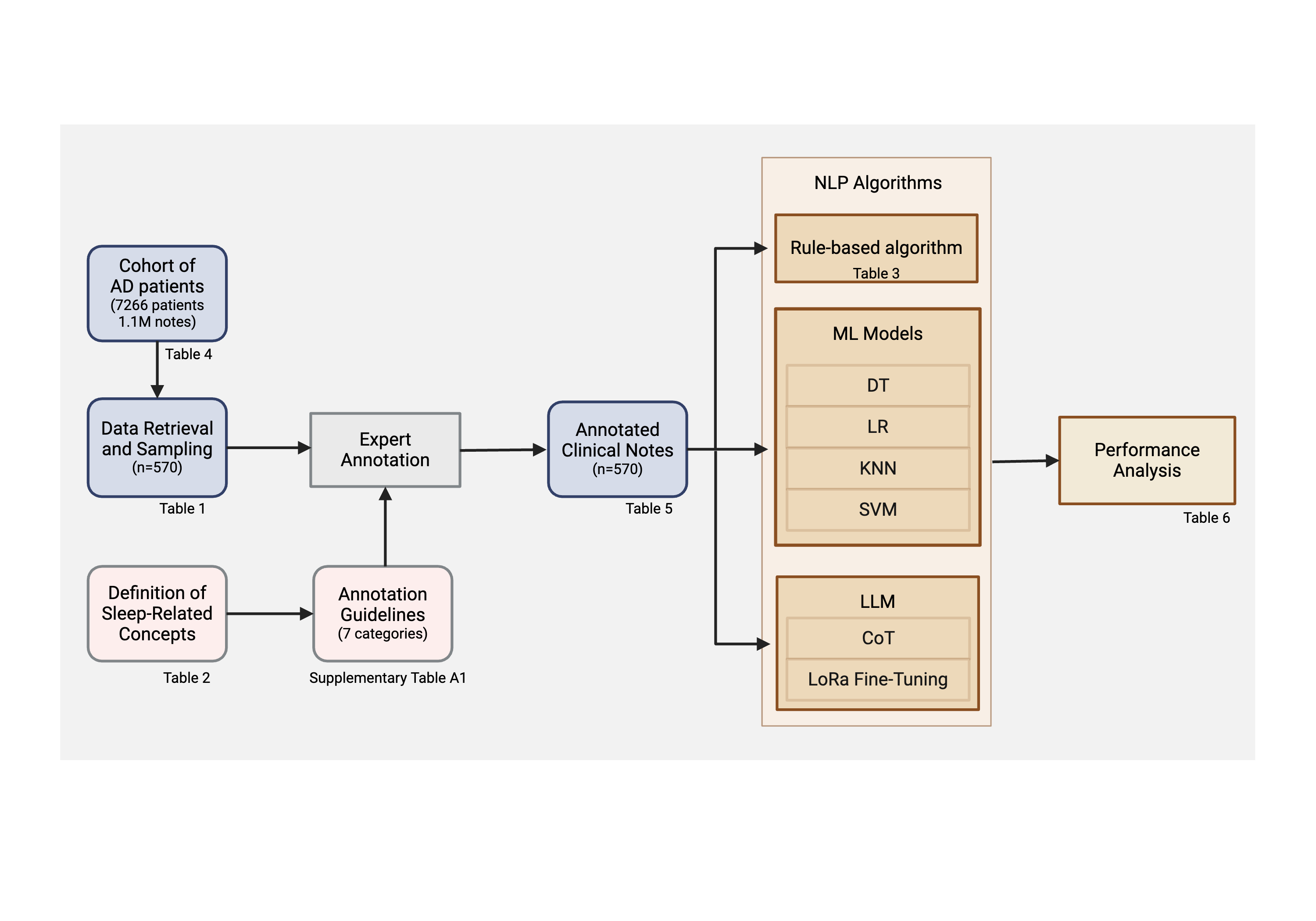
Alzheimer's Disease (AD) is the most common form of dementia in the United States. Sleep is one of the lifestyle-related factors that has been shown critical for optimal cognitive function in old age. However, there is a lack of research studying the association between sleep and AD incidence. A major bottleneck for conducting such research is that the traditional way to acquire sleep information is time-consuming, inefficient, non-scalable, and limited to patients' subjective experience. A gold standard dataset is created from manual annotation of 570 randomly sampled clinical note documents from the adSLEEP, a corpus of 192,000 de-identified clinical notes of 7,266 AD patients retrieved from the University of Pittsburgh Medical Center (UPMC). We developed a rule-based Natural Language Processing (NLP) algorithm, machine learning models, and Large Language Model(LLM)-based NLP algorithms to automate the extraction of sleep-related concepts, including snoring, napping, sleep problem, bad sleep quality, daytime sleepiness, night wakings, and sleep duration, from the gold standard dataset. Rule-based NLP algorithm achieved the best performance of F1 across all sleep-related concepts. In terms of Positive Predictive Value (PPV), rule-based NLP algorithm achieved 1.00 for daytime sleepiness and sleep duration, machine learning models: 0.95 and for napping, 0.86 for bad sleep quality and 0.90 for snoring; and LLAMA2 with finetuning achieved PPV of 0.93 for Night Wakings, 0.89 for sleep problem, and 1.00 for sleep duration. The results show that the rule-based NLP algorithm consistently achieved the best performance for all sleep concepts. This study focused on the clinical notes of patients with AD, but could be extended to general sleep information extraction for other diseases.
翻译:暂无翻译