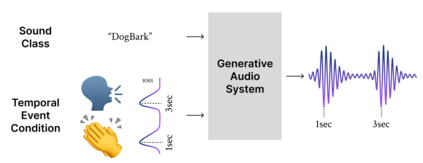
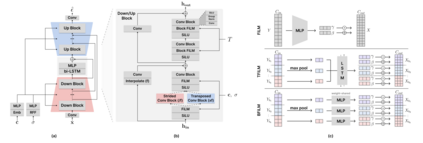
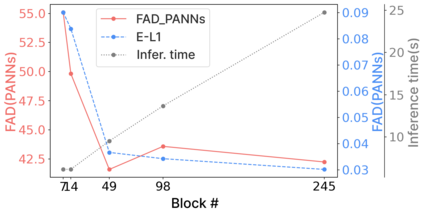
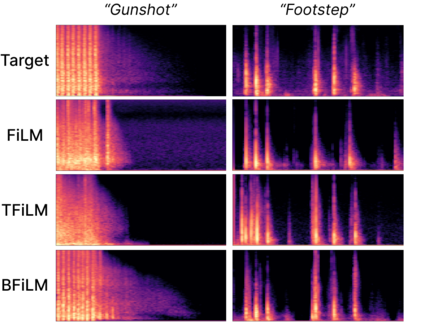
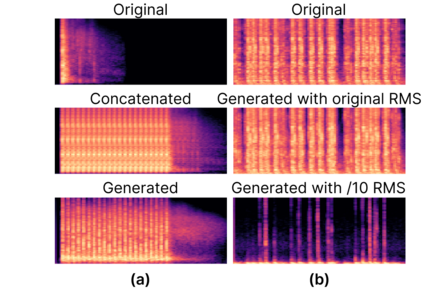
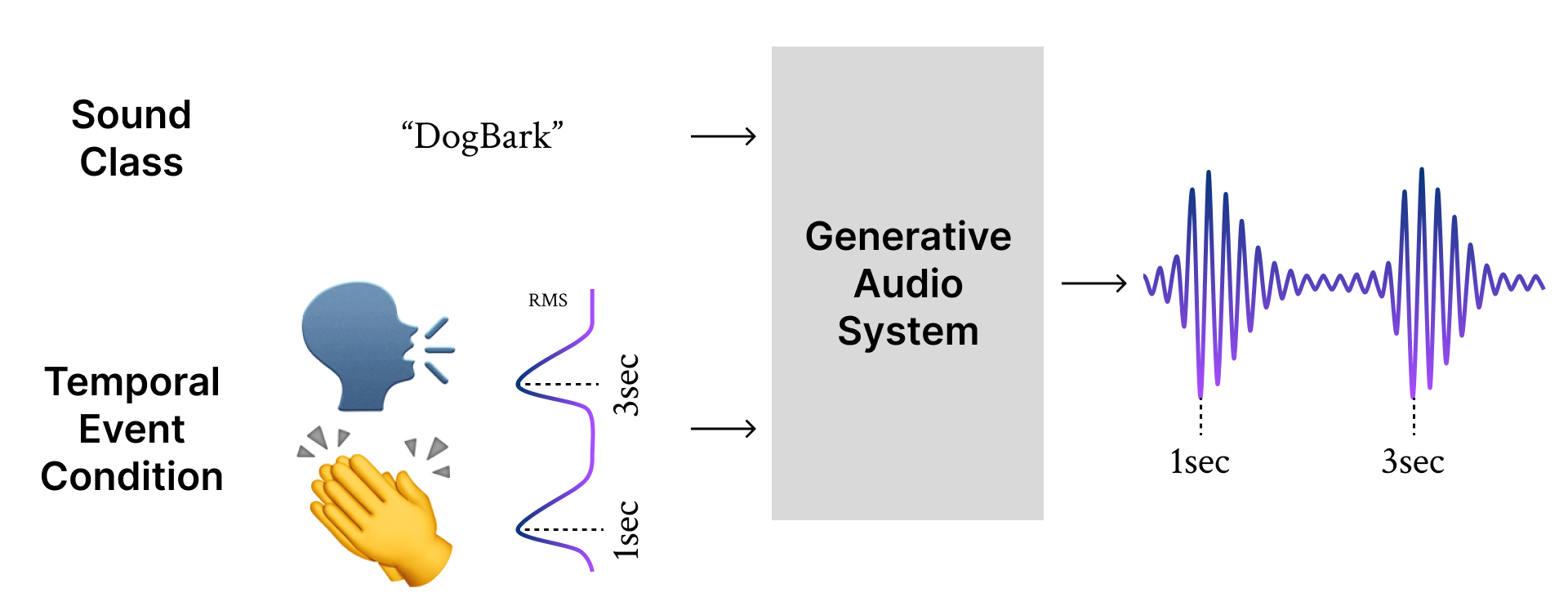
Foley sound, audio content inserted synchronously with videos, plays a critical role in the user experience of multimedia content. Recently, there has been active research in Foley sound synthesis, leveraging the advancements in deep generative models. However, such works mainly focus on replicating a single sound class or a textual sound description, neglecting temporal information, which is crucial in the practical applications of Foley sound. We present T-Foley, a Temporal-event-guided waveform generation model for Foley sound synthesis. T-Foley generates high-quality audio using two conditions: the sound class and temporal event feature. For temporal conditioning, we devise a temporal event feature and a novel conditioning technique named Block-FiLM. T-Foley achieves superior performance in both objective and subjective evaluation metrics and generates Foley sound well-synchronized with the temporal events. Additionally, we showcase T-Foley's practical applications, particularly in scenarios involving vocal mimicry for temporal event control. We show the demo on our companion website.
翻译:暂无翻译