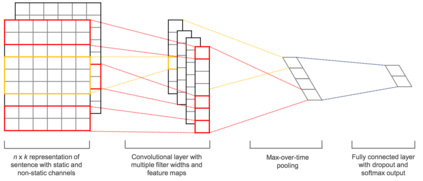
This study presents a multimodal machine learning model to predict ICD-10 diagnostic codes. We developed separate machine learning models that can handle data from different modalities, including unstructured text, semi-structured text and structured tabular data. We further employed an ensemble method to integrate all modality-specific models to generate ICD-10 codes. Key evidence was also extracted to make our prediction more convincing and explainable. We used the Medical Information Mart for Intensive Care III (MIMIC -III) dataset to validate our approach. For ICD code prediction, our best-performing model (micro-F1 = 0.7633, micro-AUC = 0.9541) significantly outperforms other baseline models including TF-IDF (micro-F1 = 0.6721, micro-AUC = 0.7879) and Text-CNN model (micro-F1 = 0.6569, micro-AUC = 0.9235). For interpretability, our approach achieves a Jaccard Similarity Coefficient (JSC) of 0.1806 on text data and 0.3105 on tabular data, where well-trained physicians achieve 0.2780 and 0.5002 respectively.
翻译:这项研究提供了一种多式机器学习模型,以预测ICD-10诊断代码。我们开发了单独的机器学习模型,可以处理不同模式的数据,包括无结构文本、半结构文本和结构化表格数据。我们进一步采用了一种混合方法,整合所有特定模式模型,以生成ICD-10代码。还提取了关键证据,使我们的预测更加可信和可以解释。我们使用“三号强化护理医疗信息网”(MIMIMIC-III)数据集来验证我们的方法。对于ICD代码预测,我们最优秀的模型(Mro-F1=0.7633,微型-AUC=0.9541)大大优于其他基线模型,包括TF-IDF(1M-F1=0.6721,微型-AUC=0.7879)和Text-CNN模型(Micro-F1=0.6569,微型-AUC=0.9235),为了解释性,我们的方法在文本数据上达到了0.1806和表式数据上0.305,受过良好训练的医生分别达到0.270和0.5802。