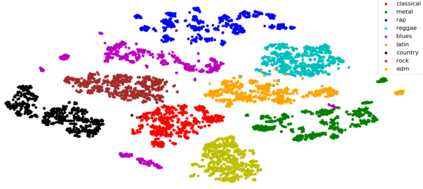
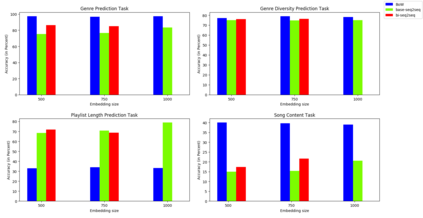
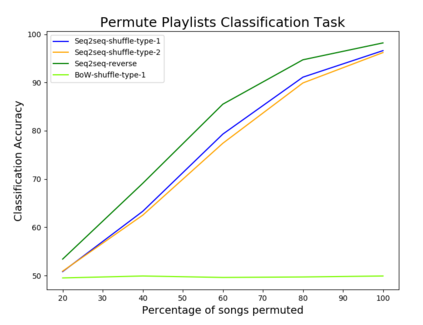
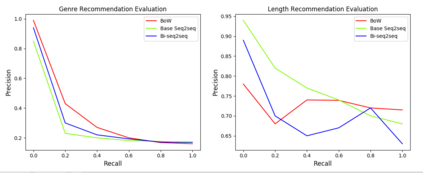
Playlists have become a significant part of our listening experience because of the digital cloud-based services such as Spotify, Pandora, Apple Music. Owing to the meteoric rise in the usage of playlists, recommending playlists is crucial to music services today. Although there has been a lot of work done in playlist prediction, the area of playlist representation hasn't received that level of attention. Over the last few years, sequence-to-sequence models, especially in the field of natural language processing, have shown the effectiveness of learned embeddings in capturing the semantic characteristics of sequences. We can apply similar concepts to music to learn fixed length representations for playlists and use those representations for downstream tasks such as playlist discovery, browsing, and recommendation. In this work, we formulate the problem of learning a fixed-length playlist representation in an unsupervised manner, using Sequence-to-sequence (Seq2seq) models, interpreting playlists as sentences and songs as words. We compare our model with two other encoding architectures for baseline comparison. We evaluate our work using the suite of tasks commonly used for assessing sentence embeddings, along with a few additional tasks pertaining to music, and a recommendation task to study the traits captured by the playlist embeddings and their effectiveness for the purpose of music recommendation.
翻译:由于基于数字云的服务,例如Spotify、Pandora、Apple Music等,播放列表已经成为我们监听经历的一个重要部分。由于播放列表的使用率的暴增,建议播放列表对今天的音乐服务至关重要。虽然在播放列表预测方面做了大量工作,但播放列表的展示领域没有受到如此关注。过去几年来,顺序到顺序模型,特别是在自然语言处理领域,展示了在捕捉序列的语义特征方面学到的嵌入器的有效性。我们可以对音乐应用类似的概念来学习播放列表的固定长度表达方式,并将这些表达方式用于下游任务,例如播放列表的发现、浏览和建议。在这项工作中,我们以不受监督的方式设计学习固定长度播放列表的问题,使用序列到顺序(Seq2seq)模型,将播放列表作为句子和歌曲词词句解释。我们将我们的模式与其他两个基本编码结构进行比较。我们用一个套式任务来评估我们的工作,用一个套式任务来评估其常规任务 — 套式任务,用一个套式任务来评估游戏任务,用一个套式任务来评估常用的任务。