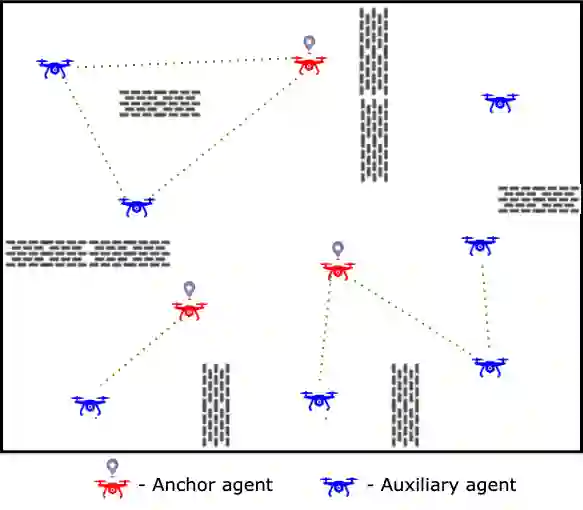
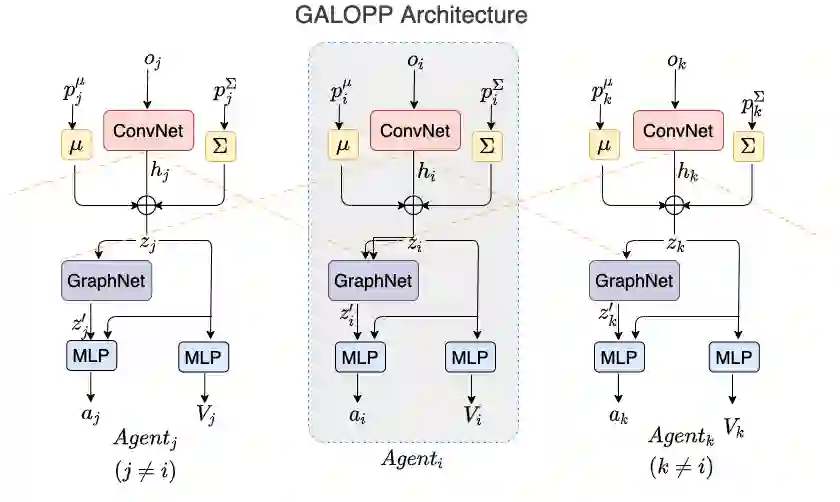
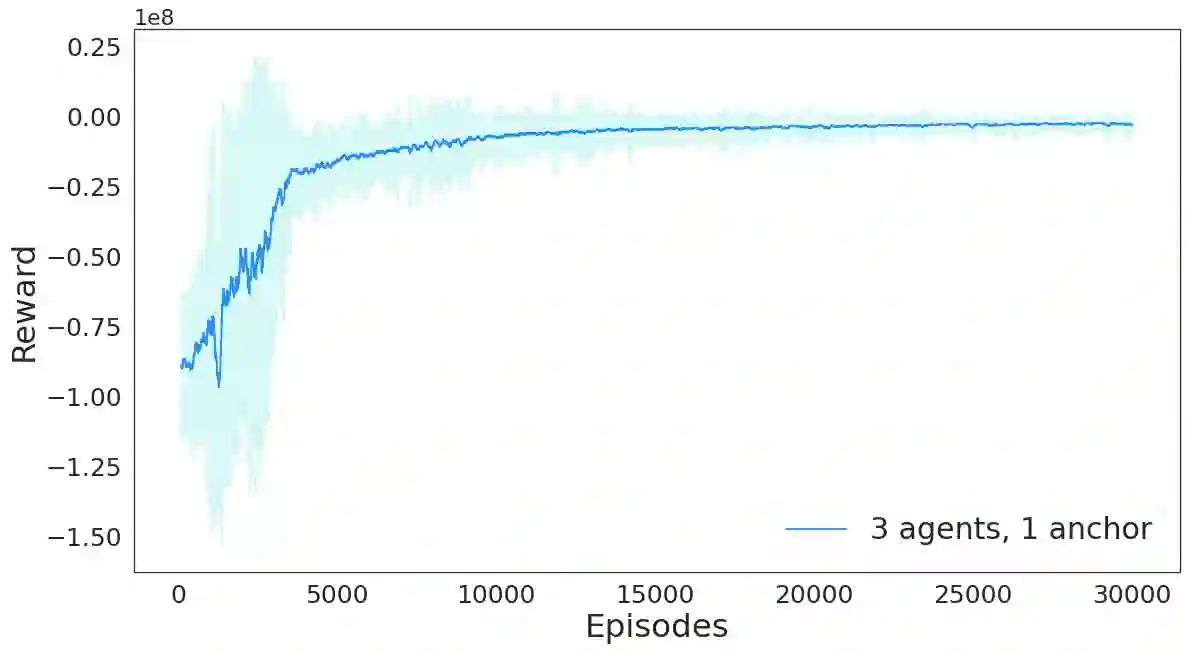
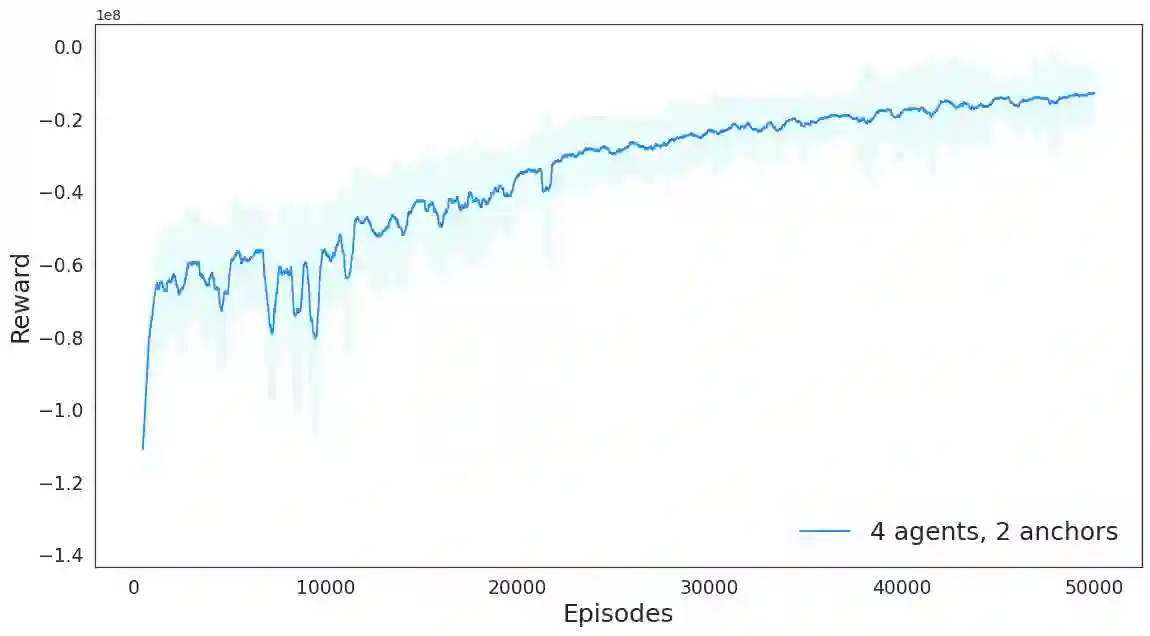
Persistently monitoring a region under localization and communication constraints is a challenging problem. In this paper, we consider a heterogenous robotic system consisting of two types of agents -- anchor agents that have accurate localization capability, and auxiliary agents that have low localization accuracy. The auxiliary agents must be within the communication range of an {anchor}, directly or indirectly to localize itself. The objective of the robotic team is to minimize the uncertainty in the environment through persistent monitoring. We propose a multi-agent deep reinforcement learning (MADRL) based architecture with graph attention called Graph Localized Proximal Policy Optimization (GALLOP), which incorporates the localization and communication constraints of the agents along with persistent monitoring objective to determine motion policies for each agent. We evaluate the performance of GALLOP on three different custom-built environments. The results show the agents are able to learn a stable policy and outperform greedy and random search baseline approaches.
翻译:持续监测地方化和通信受限的区域是一个具有挑战性的问题。在本文件中,我们考虑由两种类型的代理人组成的异质机器人系统 -- -- 定位能力准确的固定代理人和本地化准确度低的辅助代理人。辅助代理人必须处于{anchor}的通信范围之内,直接或间接地使自己本地化。机器人团队的目标是通过持续监测最大限度地减少环境中的不确定性。我们建议建立一个多剂深度强化学习(MADRL)结构,以图解为主,称为 " 本地化优化政策图表(GALLOP) ",它包括地方化和通信限制以及确定每个代理人运动政策的持续监测目标。我们评估GALLOP在三个不同的定制环境中的绩效。结果显示,这些代理人能够学习稳定的政策,超越贪婪和随机搜索基线方法。