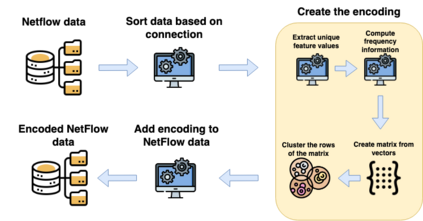
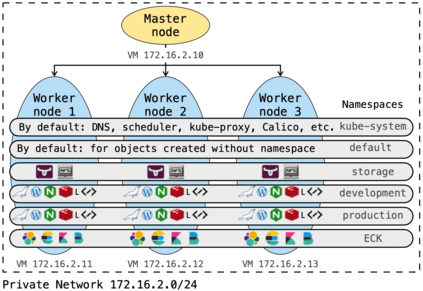
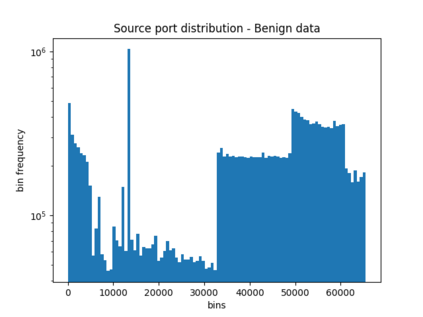
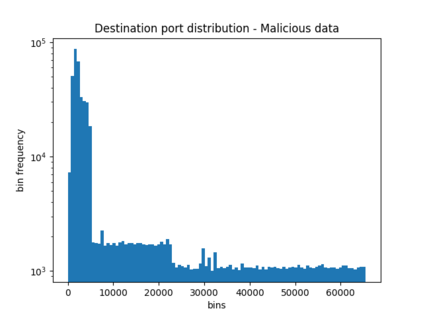
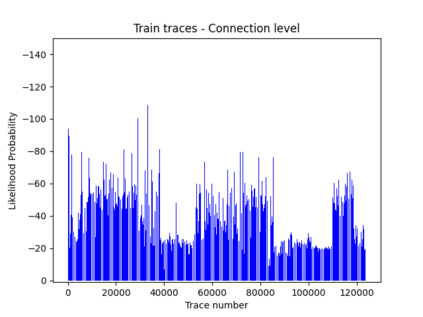
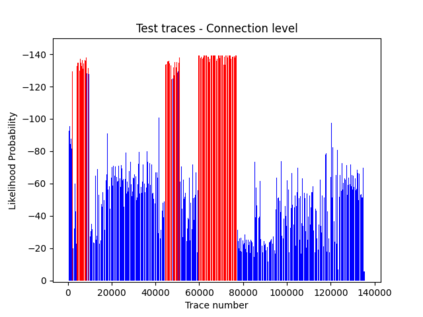
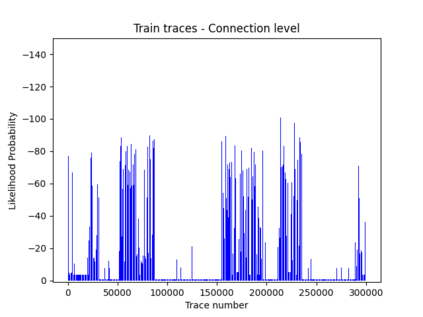
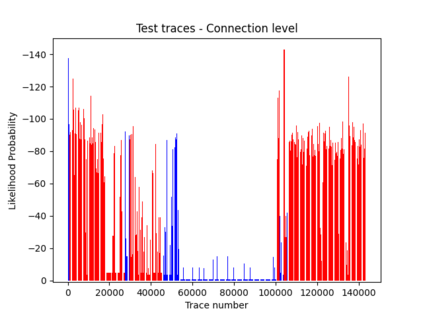
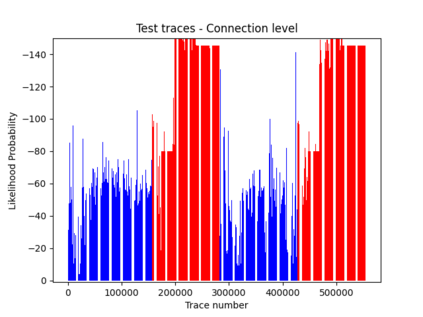
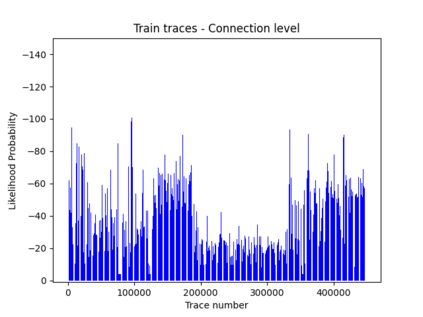
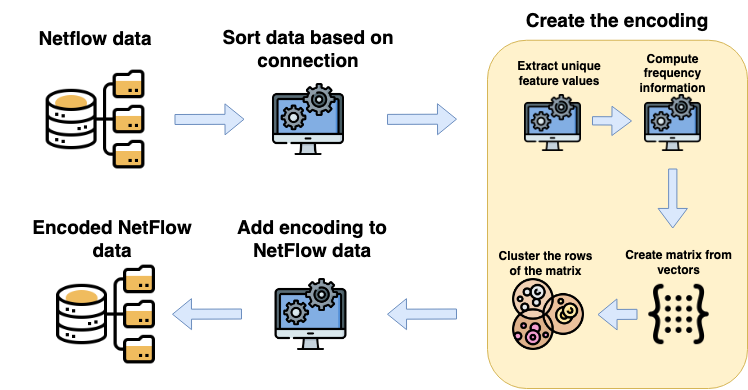
NetFlow data is a well-known network log format used by many network analysts and researchers. The advantages of using this format compared to pcap are that it contains fewer data, is less privacy intrusive, and is easier to collect and process. However, having less data does mean that this format might not be able to capture important network behaviour as all information is summarised into statistics. Much research aims to overcome this disadvantage through the use of machine learning, for instance, to detect attacks within a network. Many approaches can be used to pre-process the NetFlow data before it is used to train the machine learning algorithms. However, many of these approaches simply apply existing methods to the data, not considering the specific properties of network data. We argue that for data originating from software systems, such as NetFlow or software logs, similarities in frequency and contexts of feature values are more important than similarities in the value itself. In this work, we, therefore, propose an encoding algorithm that directly takes the frequency and the context of the feature values into account when the data is being processed. Different types of network behaviours can be clustered using this encoding, thus aiding the process of detecting anomalies within the network. From windows of these clusters obtained from monitoring a clean system, we learn state machine behavioural models for anomaly detection. These models are very well-suited to modelling the cyclic and repetitive patterns present in NetFlow data. We evaluate our encoding on a new dataset that we created for detecting problems in Kubernetes clusters and on two well-known public NetFlow datasets. The obtained performance results of the state machine models are comparable to existing works that use many more features and require both clean and infected data as training input.
翻译:NetFlow数据是许多网络分析家和研究人员使用的一种广为人知的网络日志格式。 使用这种格式比平面图的优点在于它包含的数据较少,隐私侵入较少,而且比较容易收集和处理。 但是,如果数据较少,则意味着这种格式可能无法捕捉重要的网络行为,因为所有信息都被归纳成统计数据。 许多研究的目的是通过使用机器学习来克服这一劣势,例如在网络内部检测攻击。许多方法都可用于在使用NetFlow数据来培训机器学习算法之前预先处理NetFlow数据。 但是,许多这些方法只是将现有的方法应用于数据,而没有考虑到网络数据的具体性质。我们说,对于来自软件系统的数据,例如NetFlow或软件的日志、特征值的频率和背景的相似性能可能无法捕捉到重要的网络行为。 在这项工作中,我们建议一种编码算法,直接将当前特性值的频率和背景值纳入处理中。 不同的网络行为类型可以使用这种编码进行分类, 使用这种编码, 用来对数据进行更清洁的编码, 从而帮助在网络模型中进行可比较的模型中, 从而从网络数据测算出一个系统内测算出一个更难的模型, 。