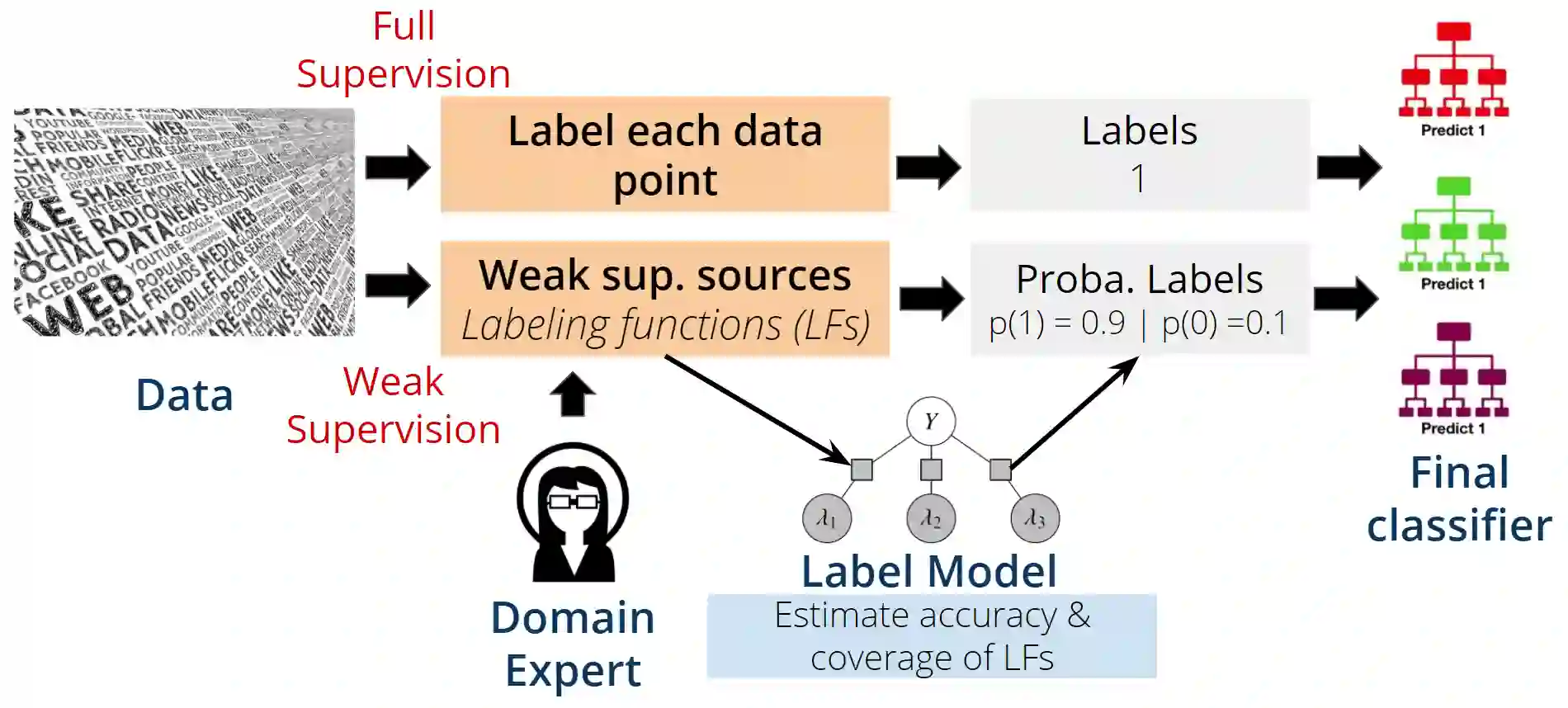
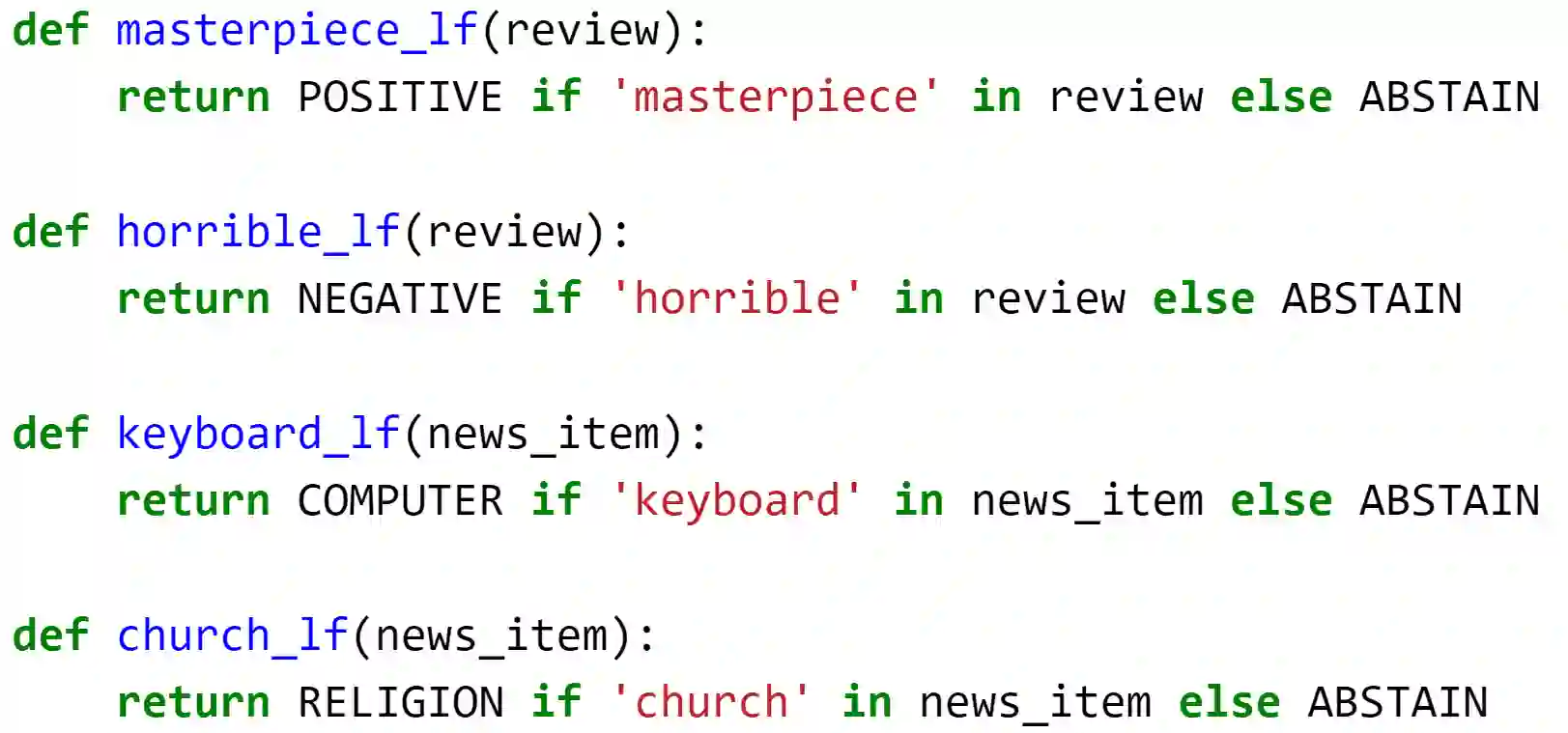
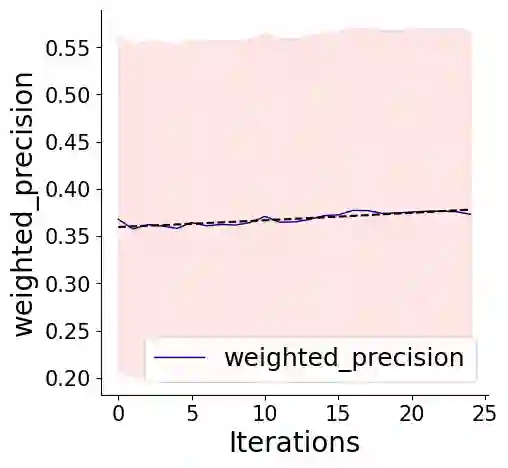
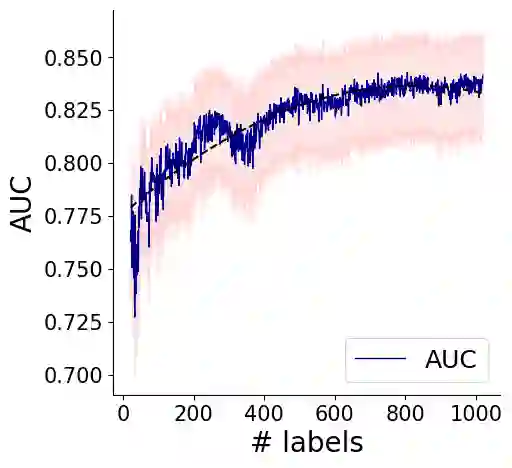
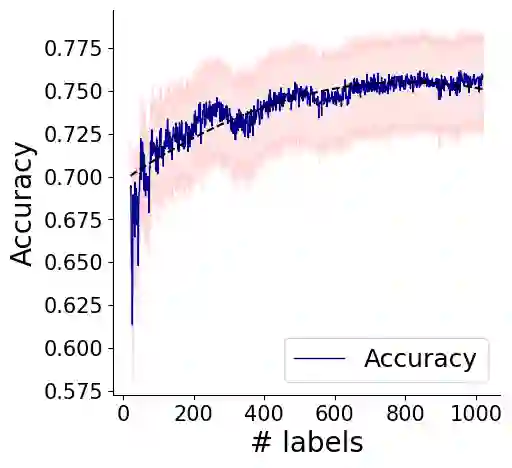
Most advanced supervised Machine Learning (ML) models rely on vast amounts of point-by-point labelled training examples. Hand-labelling vast amounts of data may be tedious, expensive, and error-prone. Recently, some studies have explored the use of diverse sources of weak supervision to produce competitive end model classifiers. In this paper, we survey recent work on weak supervision, and in particular, we investigate the Data Programming (DP) framework. Taking a set of potentially noisy heuristics as input, DP assigns denoised probabilistic labels to each data point in a dataset using a probabilistic graphical model of heuristics. We analyze the math fundamentals behind DP and demonstrate the power of it by applying it on two real-world text classification tasks. Furthermore, we compare DP with pointillistic active and semi-supervised learning techniques traditionally applied in data-sparse settings.
翻译:最先进的监督机器学习(ML)模型依靠大量的按点贴标签的培训实例。大量手工标签的数据可能是枯燥、昂贵和易出错的。最近,一些研究探索了使用各种薄弱的监督来源来产生具有竞争力的最终模式分类者。我们在本文件中调查了最近关于薄弱监督的工作,特别是调查了数据规划框架。用一套可能吵闹的杂乱的杂乱理论作为输入,DP使用一种概率性图象模型对数据集中的每个数据点指定了非无名的概率标签。我们分析了DP的数学基础,并通过将其应用于两种真实世界文本分类任务来展示其力量。此外,我们把DP与传统上在数据采集环境中使用的点性活性和半超强性学习技术进行比较。