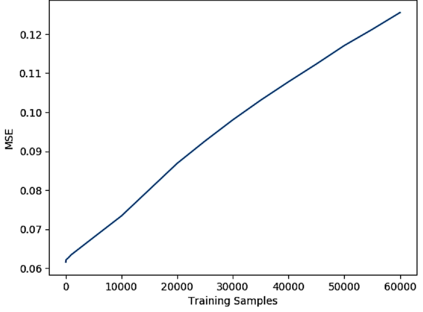
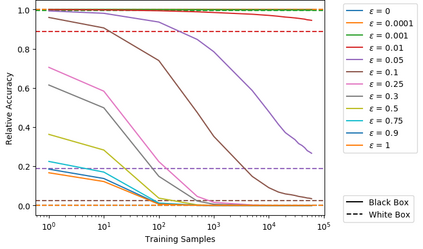
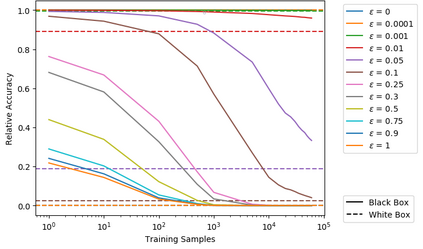
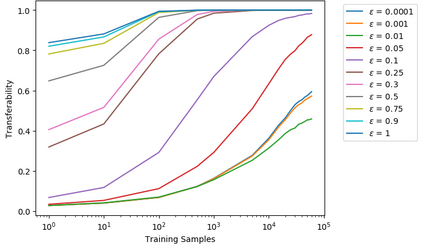
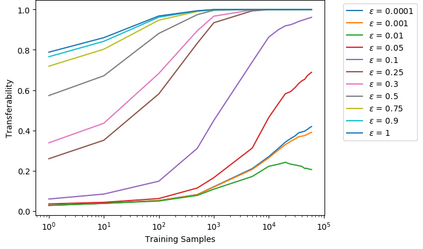
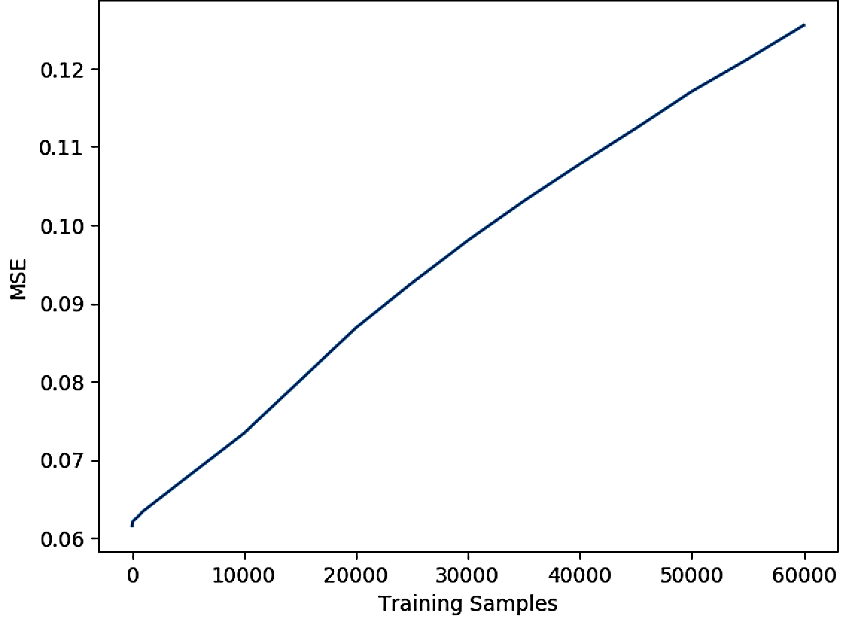
Artificial neural networks (ANNs) have gained significant popularity in the last decade for solving narrow AI problems in domains such as healthcare, transportation, and defense. As ANNs become more ubiquitous, it is imperative to understand their associated safety, security, and privacy vulnerabilities. Recently, it has been shown that ANNs are susceptible to a number of adversarial evasion attacks--inputs that cause the ANN to make high-confidence misclassifications despite being almost indistinguishable from the data used to train and test the network. This work explores to what degree finding these examples maybe aided by using side-channel information, specifically switching power consumption, of hardware implementations of ANNs. A black-box threat scenario is assumed, where an attacker has access to the ANN hardware's input, outputs, and topology, but the trained model parameters are unknown. Then, a surrogate model is trained to have similar functional (i.e. input-output mapping) and switching power characteristics as the oracle (black-box) model. Our results indicate that the inclusion of power consumption data increases the fidelity of the model extraction by up to 30 percent based on a mean square error comparison of the oracle and surrogate weights. However, transferability of adversarial examples from the surrogate to the oracle model was not significantly affected.
翻译:过去十年来,人工神经网络(ANNS)在解决保健、交通和国防等领域内狭隘的AI问题方面取得了显著的受欢迎程度。随着ANNS越来越普遍,必须了解它们相关的安全、安保和隐私脆弱性。最近,人们已经表明,ANNS很容易受到一些对抗性规避攻击-投入,导致ANN几乎无法区分用于培训和测试网络的数据,但导致高度信任误判的模型几乎无法与用于培训和测试网络的数据区分。这项工作探索了这些例子的发现程度,可能因为使用侧通道信息,特别是转换电耗,对ANNS硬件的硬件实施而有所帮助。假设了黑箱威胁情景,攻击者可以接触到ANN硬件的投入、输出和表面学,但经过培训的模型参数却不为人所知。随后,一个超导模型被训练成类似的功能模式(即输入-输出映射图)和变换电源特征(黑箱)模型(黑箱)模型。我们得出的结果表明,将电力提取数据的比重性从30级提高到了标准的比重。我们没有显示,将指数的比重数据比重从指数的比重提高到了标准。