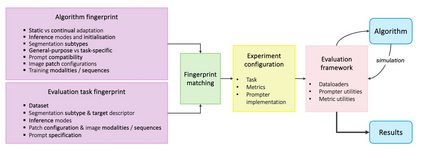
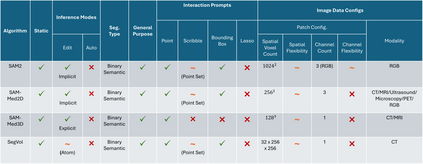
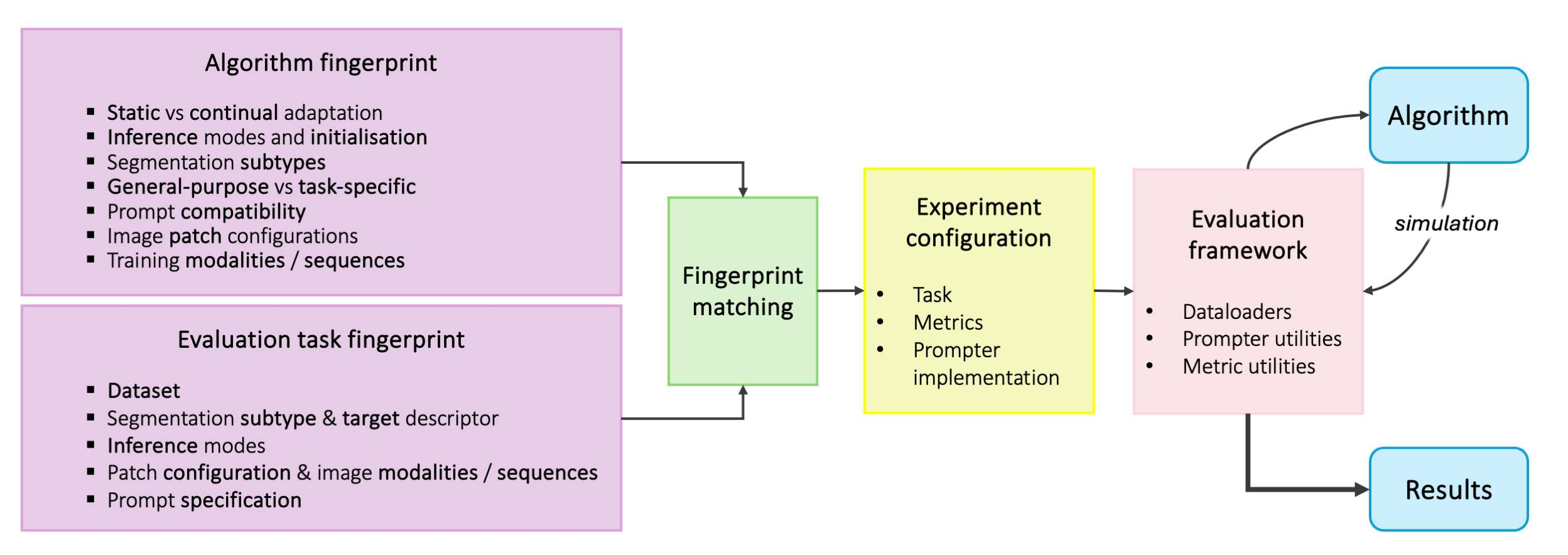
Interactive segmentation is a promising strategy for building robust, generalisable algorithms for volumetric medical image segmentation. However, inconsistent and clinically unrealistic evaluation hinders fair comparison and misrepresents real-world performance. We propose a clinically grounded methodology for defining evaluation tasks and metrics, and built a software framework for constructing standardised evaluation pipelines. We evaluate state-of-the-art algorithms across heterogeneous and complex tasks and observe that (i) minimising information loss when processing user interactions is critical for model robustness, (ii) adaptive-zooming mechanisms boost robustness and speed convergence, (iii) performance drops if validation prompting behaviour/budgets differ from training, (iv) 2D methods perform well with slab-like images and coarse targets, but 3D context helps with large or irregularly shaped targets, (v) performance of non-medical-domain models (e.g. SAM2) degrades with poor contrast and complex shapes.
翻译:暂无翻译