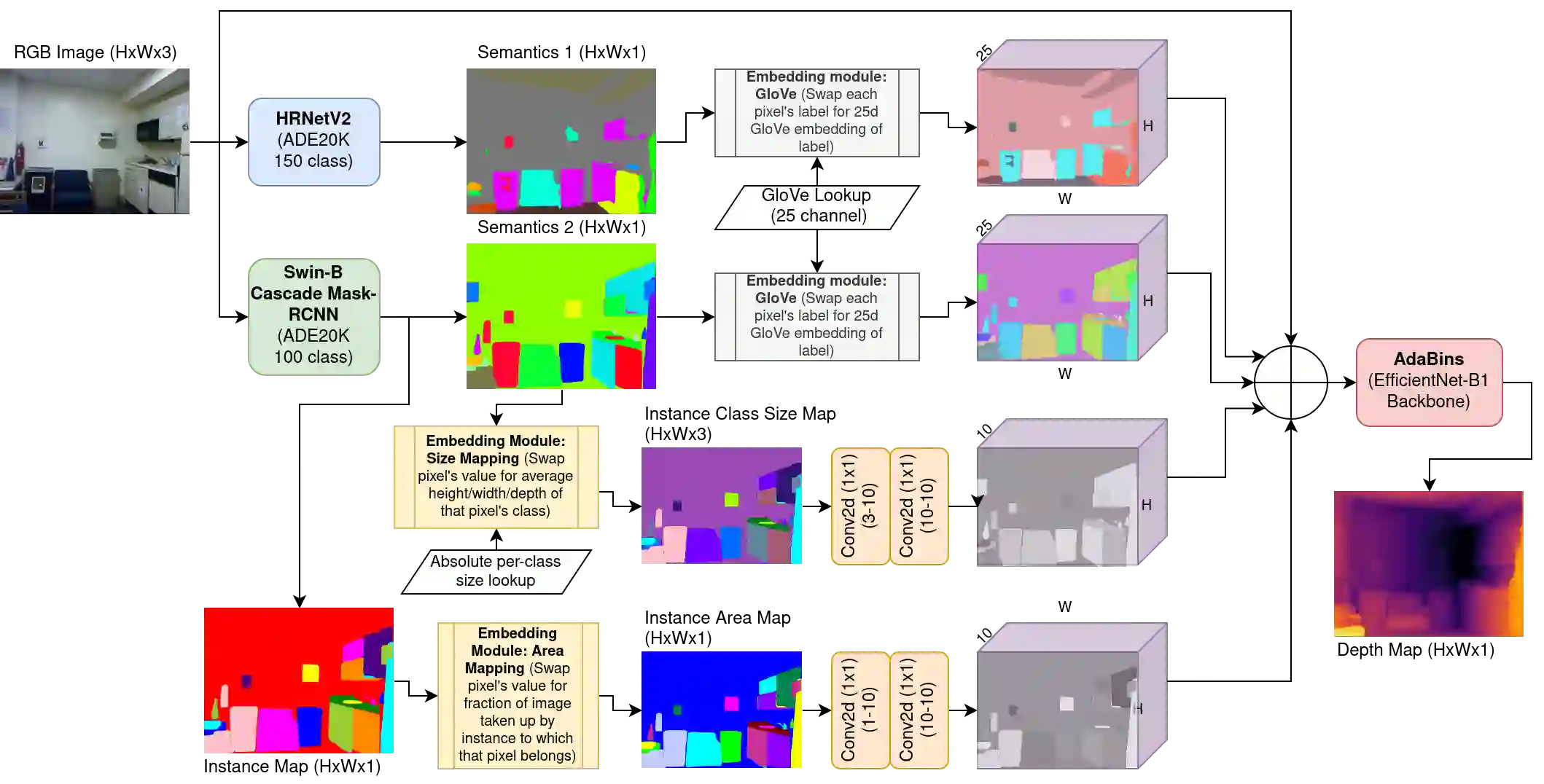
Monocular depth estimation (MDE) aims to transform an RGB image of a scene into a pixelwise depth map from the same camera view. It is fundamentally ill-posed due to missing information: any single image can have been taken from many possible 3D scenes. Part of the MDE task is, therefore, to learn which visual cues in the image can be used for depth estimation, and how. With training data limited by cost of annotation or network capacity limited by computational power, this is challenging. In this work we demonstrate that explicitly injecting visual cue information into the model is beneficial for depth estimation. Following research into biological vision systems, we focus on semantic information and prior knowledge of object sizes and their relations, to emulate the biological cues of relative size, familiar size, and absolute size. We use state-of-the-art semantic and instance segmentation models to provide external information, and exploit language embeddings to encode relational information between classes. We also provide a prior on the average real-world size of objects. This external information overcomes the limitation in data availability, and ensures that the limited capacity of a given network is focused on known-helpful cues, therefore improving performance. We experimentally validate our hypothesis and evaluate the proposed model on the widely used NYUD2 indoor depth estimation benchmark. The results show improvements in depth prediction when the semantic information, size prior and instance size are explicitly provided along with the RGB images, and our method can be easily adapted to any depth estimation system.
翻译:单心深度估计( MDE) 旨在将一个场景的 RGB 图像转换成同一相机视图的像素深度映像。 由于缺乏信息, 从根本上说, 根本不正确: 任何单一图像都可以从许多可能的 3D 场景中采集。 因此, MDE 任务的一部分是了解图像中哪些视觉提示可用于深度估测, 以及如何使用。 由于培训数据受注释成本或网络能力限制, 计算能力限制了, 这一点具有挑战性。 在这项工作中, 我们证明向模型明确输入视觉提示信息有利于深度估测。 在对生物视觉系统进行研究之后, 我们侧重于语义性图像信息以及先前关于对象大小及其关系的知识, 以学习相对大小、 熟悉大小和绝对大小的生物线索。 因此, 我们使用状态的语义分解模型和实例分解模型来提供外部关系信息的嵌入。 我们还在对实际天体的平均规模进行事先的调整。 这种外部信息克服了数据获取的局限性, 并且确保了对实验性深度的深度的精确度评估能力, 因此, 我们使用的网络的精确度的精确度, 将用来显示我们之前的模型 的精确度 。