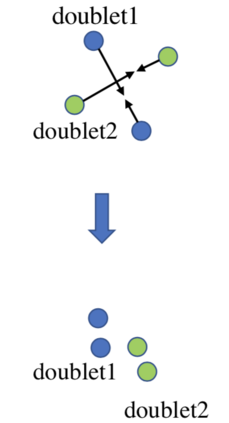
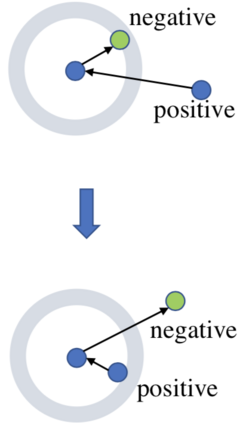
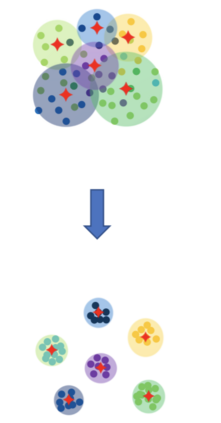
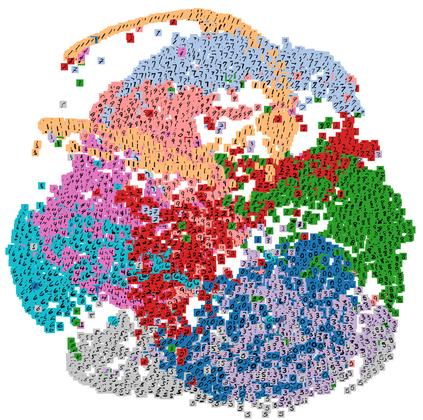
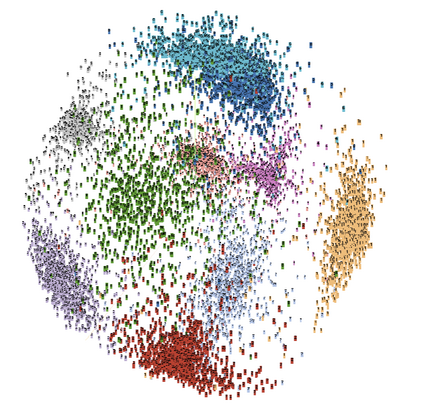
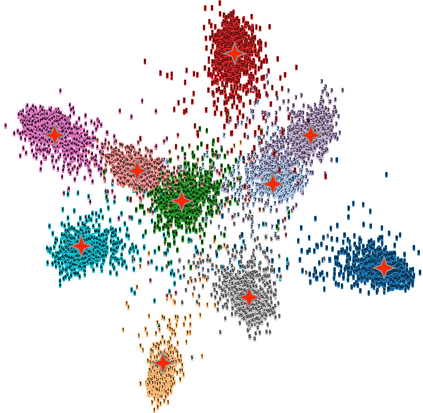
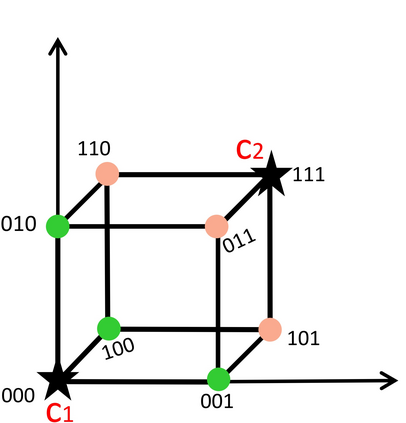
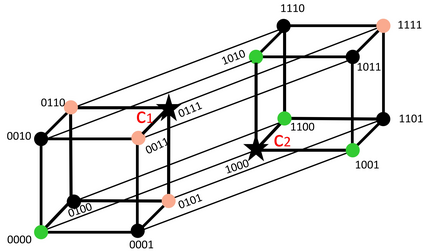
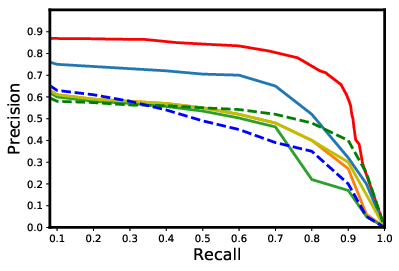
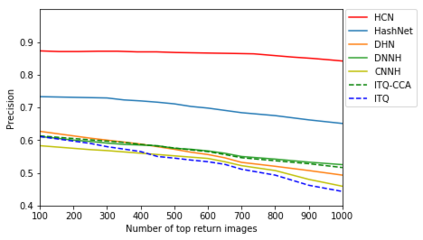
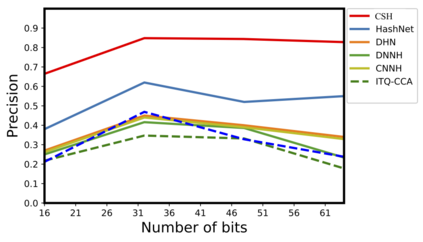
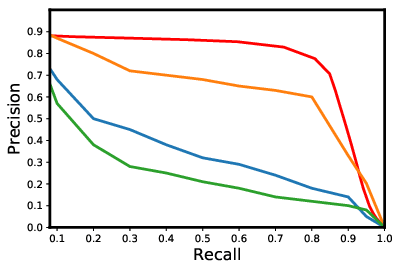
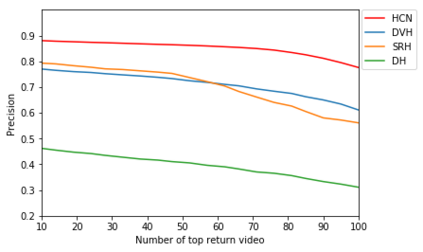
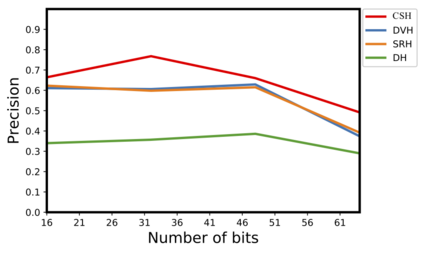
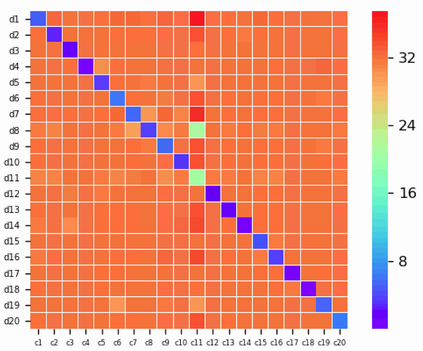
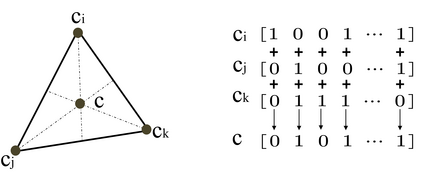Existing data-dependent hashing methods usually learn hash functions from pairwise or triplet data relationships, which only capture the data similarity locally, and often suffer from low learning efficiency and low collision rate. In this work, we propose a new \emph{global} similarity metric, termed as \emph{central similarity}, with which the hash codes of similar data pairs are encouraged to approach a common center and those for dissimilar pairs to converge to different centers, to improve hash learning efficiency and retrieval accuracy. We principally formulate the computation of the proposed central similarity metric by introducing a new concept, i.e., \emph{hash center} that refers to a set of data points scattered in the Hamming space with a sufficient mutual distance between each other. We then provide an efficient method to construct well separated hash centers by leveraging the Hadamard matrix and Bernoulli distributions. Finally, we propose the Central Similarity Quantization (CSQ) that optimizes the central similarity between data points w.r.t.\ their hash centers instead of optimizing the local similarity. CSQ is generic and applicable to both image and video hashing scenarios. Extensive experiments on large-scale image and video retrieval tasks demonstrate that CSQ can generate cohesive hash codes for similar data pairs and dispersed hash codes for dissimilar pairs, achieving a noticeable boost in retrieval performance, i.e. 3\%-20\% in mAP over the previous state-of-the-arts \footnote{The code is at: \url{https://github.com/yuanli2333/Hadamard-Matrix-for-hashing}}
翻译:依赖数据的散列方法通常从对称或三重数据关系中学习散列函数,这种关系只反映当地的数据相似性,而且往往受到低学习效率和低碰撞率的影响。在这项工作中,我们提出一个新的相近度指标,称为 emph{global},鼓励类似数据配对的散列代码接近一个共同中心,鼓励不同配对的散列代码接近一个共同中心,以提高散列学习效率和检索准确性。我们主要通过引入一个新概念来计算拟议的中央类似度指标,即: e.\emph{hash} 中心,这是指在Hamming空间分散的一组数据点,彼此之间有足够的距离。然后我们提出一种高效的方法,通过利用哈达马特矩阵和Bernoulli的分布,来构建一个共同中心。我们建议中央相似性量化(CSQQ),以优化数据点之间的中央相似性比值(w.r.t.h) 和它们的 has-20 中心,而不是最清晰的缩缩缩缩缩的 CQ 和 Cal- dalalal 图像,可以产生一个可应用的大规模图像。