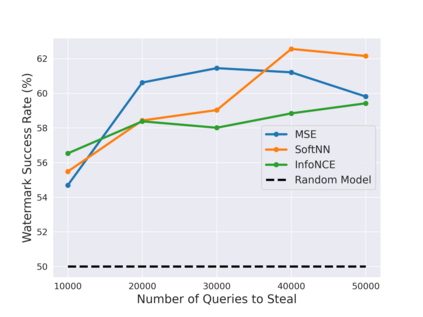
Self-Supervised Learning (SSL) is an increasingly popular ML paradigm that trains models to transform complex inputs into representations without relying on explicit labels. These representations encode similarity structures that enable efficient learning of multiple downstream tasks. Recently, ML-as-a-Service providers have commenced offering trained SSL models over inference APIs, which transform user inputs into useful representations for a fee. However, the high cost involved to train these models and their exposure over APIs both make black-box extraction a realistic security threat. We thus explore model stealing attacks against SSL. Unlike traditional model extraction on classifiers that output labels, the victim models here output representations; these representations are of significantly higher dimensionality compared to the low-dimensional prediction scores output by classifiers. We construct several novel attacks and find that approaches that train directly on a victim's stolen representations are query efficient and enable high accuracy for downstream models. We then show that existing defenses against model extraction are inadequate and not easily retrofitted to the specificities of SSL.
翻译:自我监督学习(SSL)是一个日益受欢迎的ML模式,它培训各种模型,将复杂的投入转变为不依赖明确标签的表述形式。这些模型对相似结构进行编码,以便高效地学习多个下游任务。最近,ML-as-services供应商开始提供经过培训的SSL模型,以取代推断的APIs。将用户投入转化为有用的表述方式,收取一定的费用。然而,培训这些模型的高昂成本及其在API的接触,使黑盒提取成为现实的安全威胁。我们因此探索了对SSL的攻击模式。与输出标签的传统分类模式的偷窃模式不同,受害者模型在这里的输出形式;这些表述与分类者的低维度预测分数输出相比,具有显著的高度多维度。我们制造了几起新式攻击,发现直接培训受害者被窃的表述方式是高效的,使下游模式的高度精准性。我们然后表明,现有的针对模型提取的防御手段不足,不易与SSL的特性相适应。