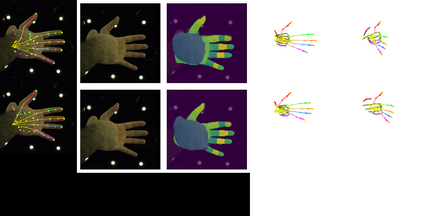
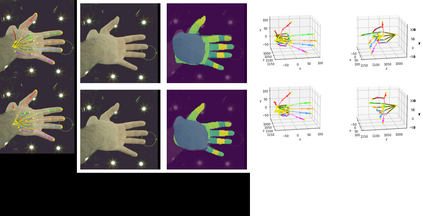
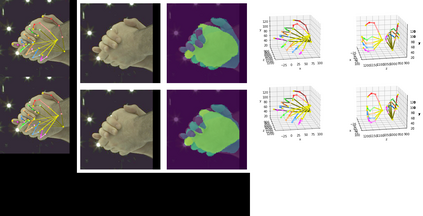
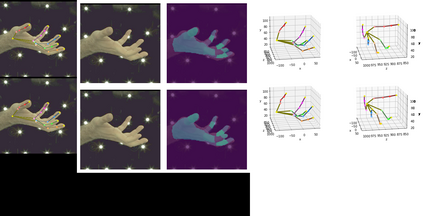
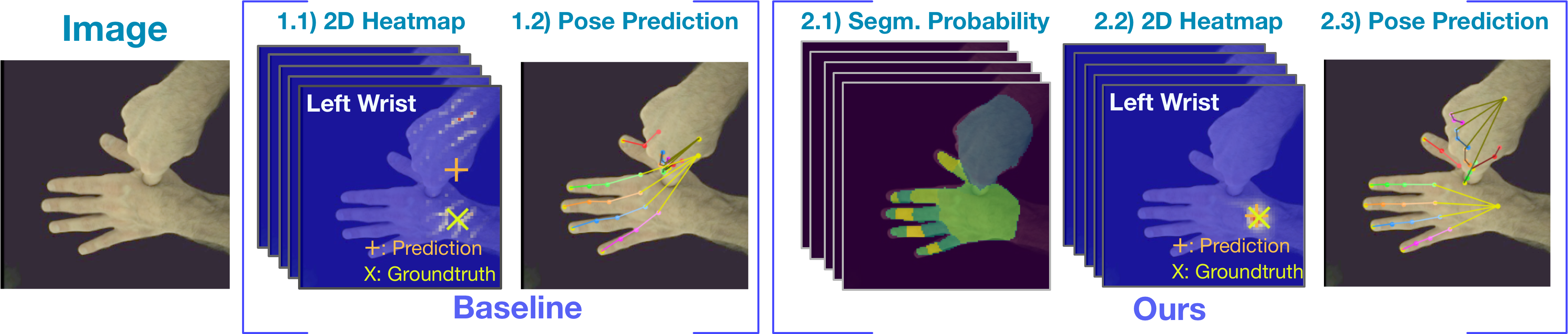
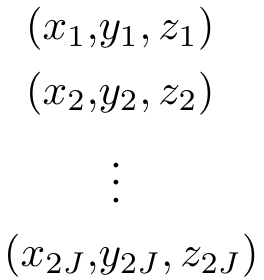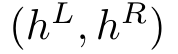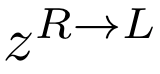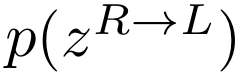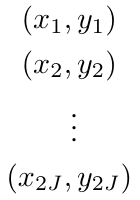In natural conversation and interaction, our hands often overlap or are in contact with each other. Due to the homogeneous appearance of hands, this makes estimating the 3D pose of interacting hands from images difficult. In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image. The method consists of two interwoven branches that process the input imagery into a per-pixel semantic part segmentation mask and a visual feature volume. In contrast to prior work, we do not decouple the segmentation from the pose estimation stage, but rather leverage the per-pixel probabilities directly in the downstream pose estimation task. To do so, the part probabilities are merged with the visual features and processed via fully-convolutional layers. We experimentally show that the proposed approach achieves new state-of-the-art performance on the InterHand2.6M dataset for both single and interacting hands across all metrics. We provide detailed ablation studies to demonstrate the efficacy of our method and to provide insights into how the modelling of pixel ownership affects single and interacting hand pose estimation. Our code will be released for research purposes.
翻译:在自然的谈话和互动中,我们的双手往往相互重叠或相互接触。由于手的外观相似,因此很难用图像来估计3D的相互作用手的外形。在本文中,我们证明自我相似性以及由此在将像素观测分解到各个手及其部位方面产生的模糊性是最终3D造成错误的主要原因。受这种洞察力的驱使,我们提议DIGIT,这是从单一的单向图像中估算两只交互手的3D构成的新颖方法。这个方法由两个相互交织的分支组成,将输入的图像处理成每像素解析部分的遮掩和视觉特征量。与以前的工作不同,我们并不将分解到各手的像素观察,而是直接利用下游每像素的概率进行估算任务。要做到这一点,部分的概率与视觉特征相结合,通过完全变异层处理。我们实验显示拟议的方法在InterHand2M6的全方位分解面图象和视觉特征音量体中实现新的状态性表现。我们为单一的模型化研究提供一个方向,以便显示我们所有的图像的图象分析。