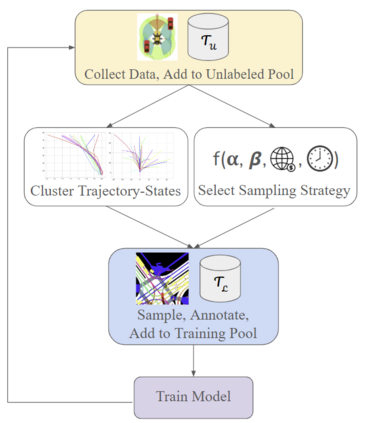
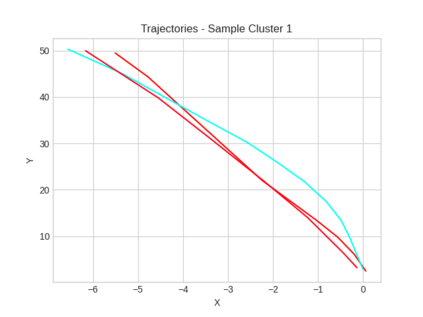
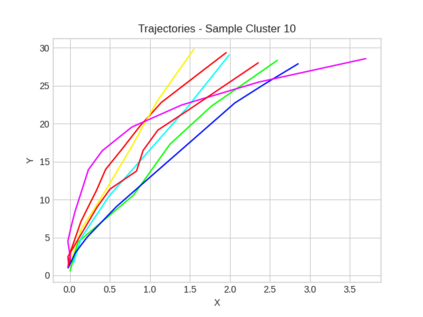
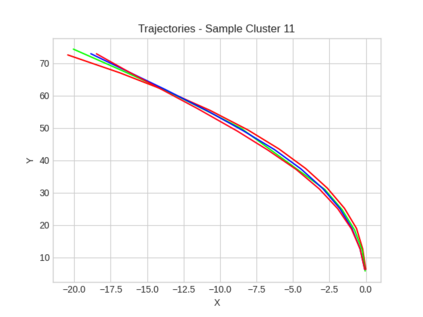
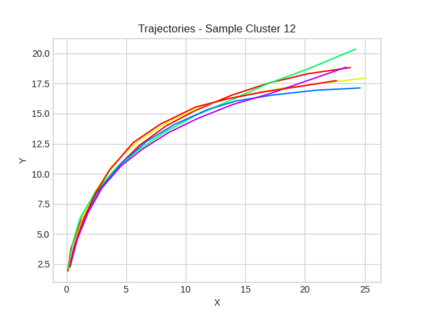
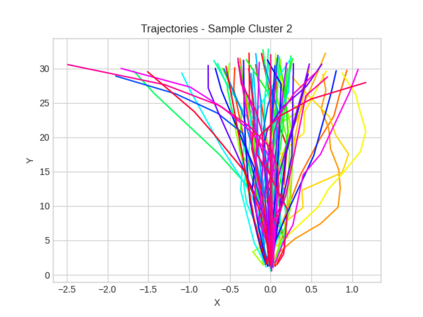
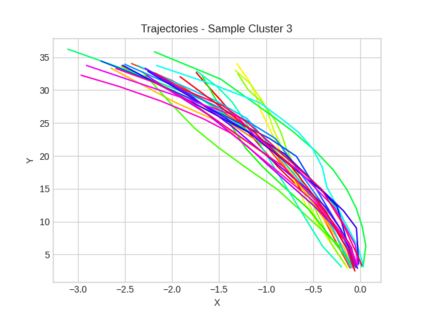
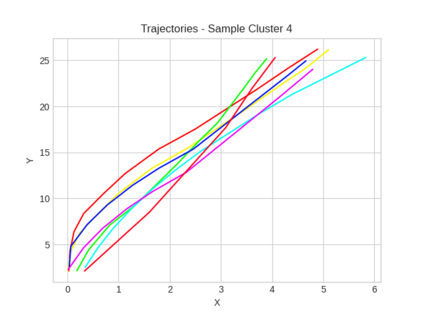
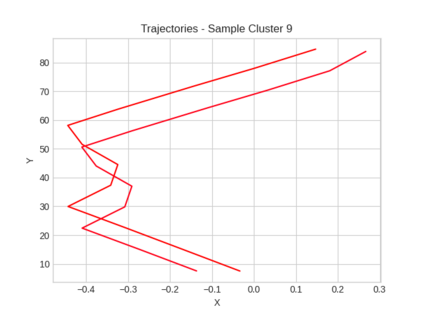
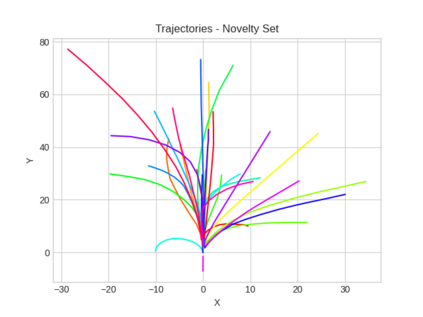
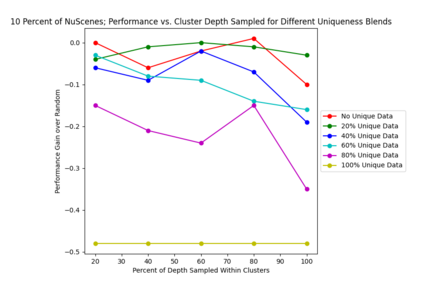
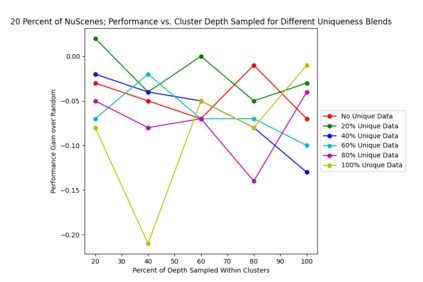
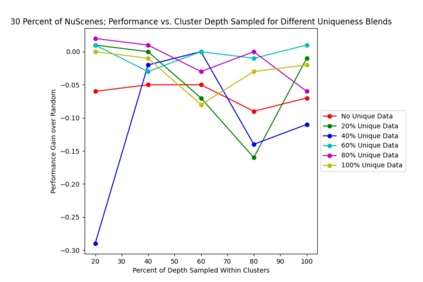
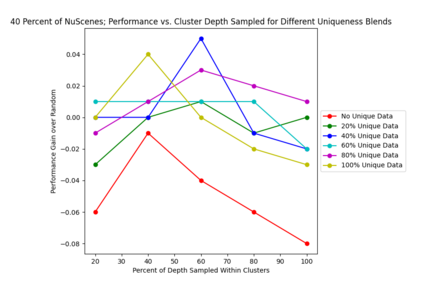
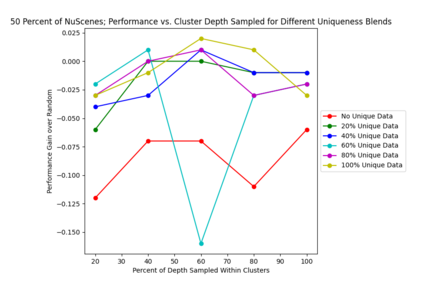
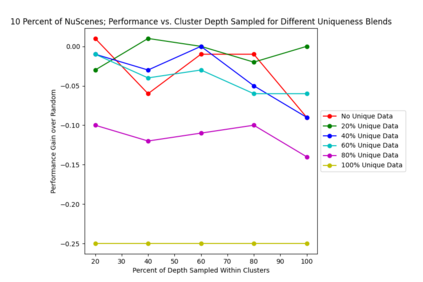
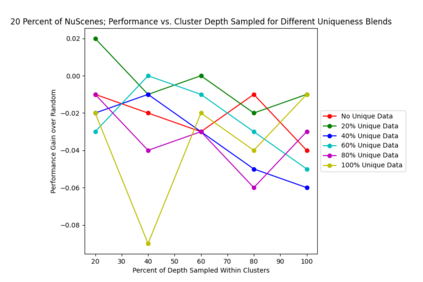
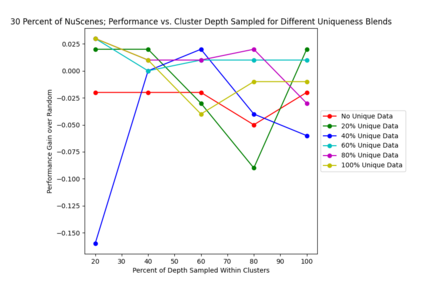
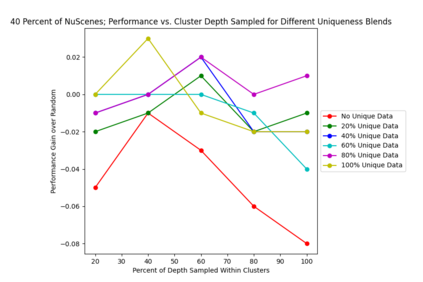
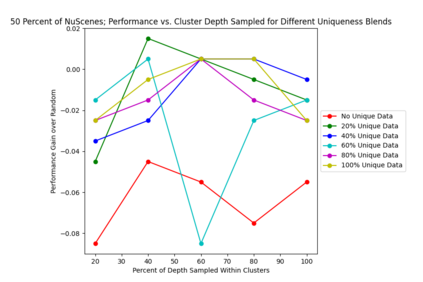
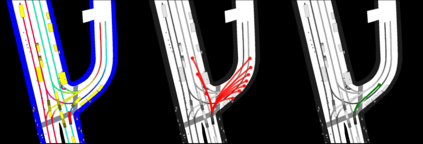
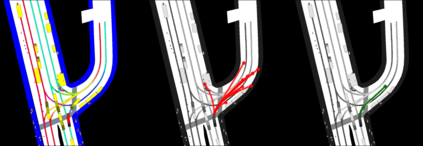
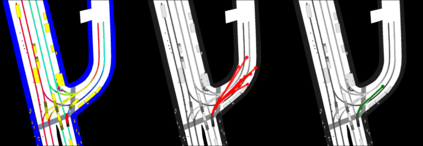
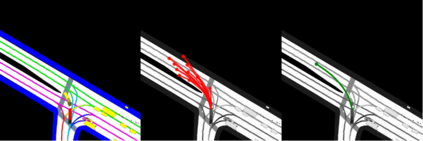
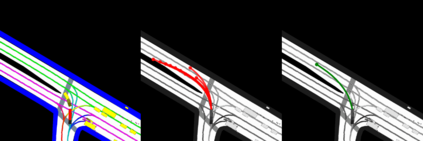
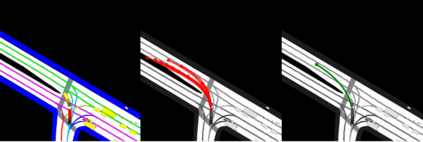
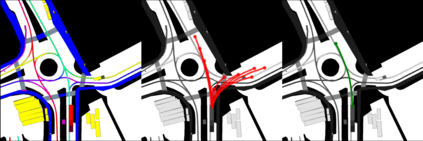
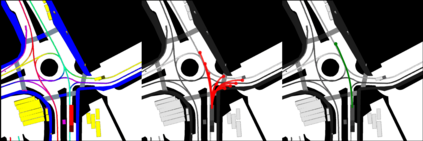
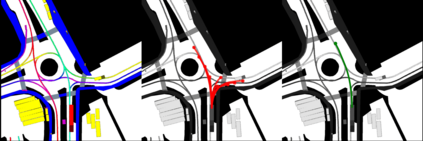
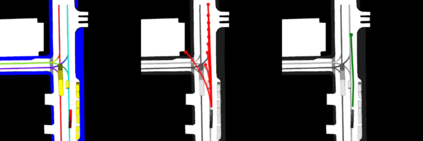
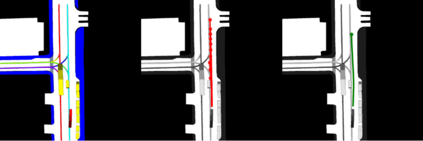
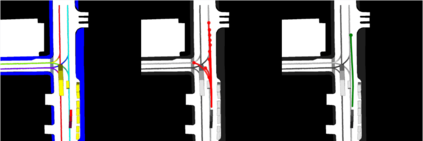
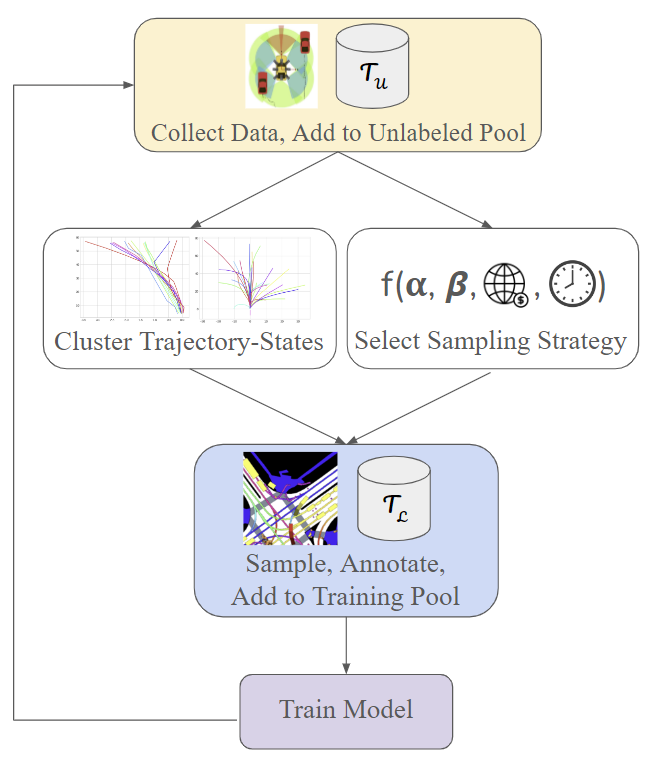
This study investigates the use of trajectory and dynamic state information for efficient data curation in autonomous driving machine learning tasks. We propose methods for clustering trajectory-states and sampling strategies in an active learning framework, aiming to reduce annotation and data costs while maintaining model performance. Our approach leverages trajectory information to guide data selection, promoting diversity in the training data. We demonstrate the effectiveness of our methods on the trajectory prediction task using the nuScenes dataset, showing consistent performance gains over random sampling across different data pool sizes, and even reaching sub-baseline displacement errors at just 50% of the data cost. Our results suggest that sampling typical data initially helps overcome the ''cold start problem,'' while introducing novelty becomes more beneficial as the training pool size increases. By integrating trajectory-state-informed active learning, we demonstrate that more efficient and robust autonomous driving systems are possible and practical using low-cost data curation strategies.
翻译:暂无翻译