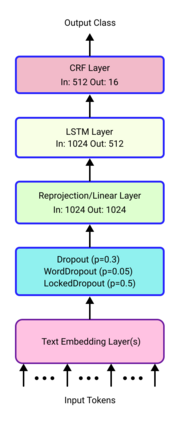
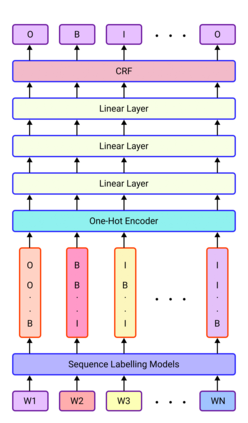
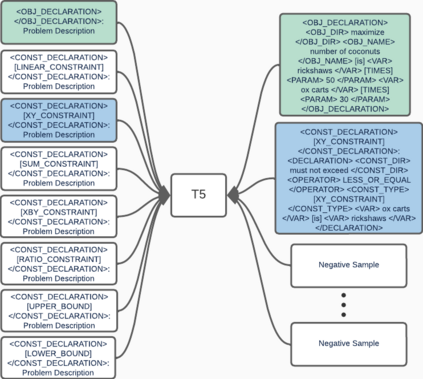
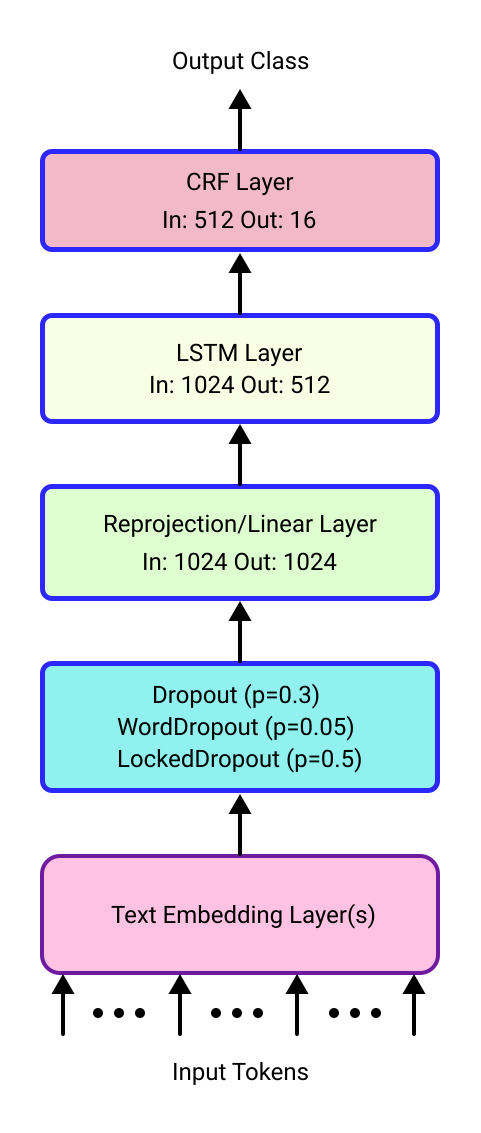
We propose an ensemble approach to predict the labels in linear programming word problems. The entity identification and the meaning representation are two types of tasks to be solved in the NL4Opt competition. We propose the ensembleCRF method to identify the named entities for the first task. We found that single models didn't improve for the given task in our analysis. A set of prediction models predict the entities. The generated results are combined to form a consensus result in the ensembleCRF method. We present an ensemble text generator to produce the representation sentences for the second task. We thought of dividing the problem into multiple small tasks due to the overflow in the output. A single model generates different representations based on the prompt. All the generated text is combined to form an ensemble and produce a mathematical meaning of a linear programming problem.
翻译:我们建议了一种混合的方法来预测线性编程单词问题中的标签。实体识别和含义表示是NL4Opt竞争中需要解决的两种任务类型。我们建议了用于确定第一个任务中指定实体的混合式CRF方法。我们发现单一模型没有改进我们分析中给定的任务。一套预测模型预测了各个实体。所产生的结果合在一起形成共同式CRF方法的共识结果。我们提出了一个组合式文本生成器来产生第二个任务的表述句。我们设想了将问题分为多个小任务,因为产出溢出。一个单一模型产生基于迅速的不同表述。所有生成的文本组合成一个组合,产生线性编程问题的数学含义。