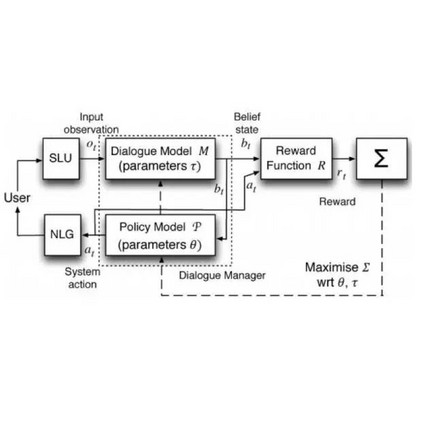
Building open-domain dialogue systems capable of rich human-like conversational ability is one of the fundamental challenges in language generation. However, even with recent advancements in the field, existing open-domain generative models fail to capture and utilize external knowledge, leading to repetitive or generic responses to unseen utterances. Current work on knowledge-grounded dialogue generation primarily focuses on persona incorporation or searching a fact-based structured knowledge source such as Wikipedia. Our method takes a broader and simpler approach, which aims to improve the raw conversation ability of the system by mimicking the human response behavior through casual interactions found on social media. Utilizing a joint retriever-generator setup, the model queries a large set of filtered comment data from Reddit to act as additional context for the seq2seq generator. Automatic and human evaluations on open-domain dialogue datasets demonstrate the effectiveness of our approach.
翻译:建立能够丰富人性谈话能力的开放域对话系统是语言生成的基本挑战之一。然而,即使最近在实地取得了进步,现有的开放域基因模型也未能捕捉和利用外部知识,导致对无形言论的重复或一般性反应。目前关于知识型对话生成的工作主要侧重于个人整合或搜索像维基百科这样的基于事实的结构性知识源。我们的方法采取更广泛、更简单的方法,旨在通过在社交媒体上发现的临时互动模拟人类反应行为来提高系统的原始对话能力。利用联合检索器-生成器设置,模型询问来自Redddit的大量经过过滤的评论数据,以作为后方2eq生成器的附加背景。对开放式对话数据集的自动和人为评价显示了我们的方法的有效性。