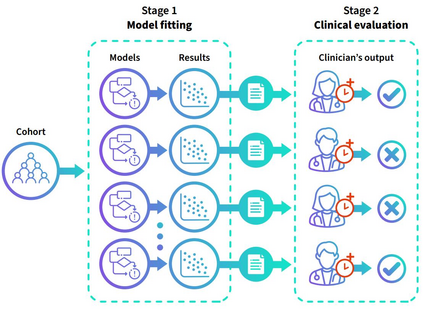
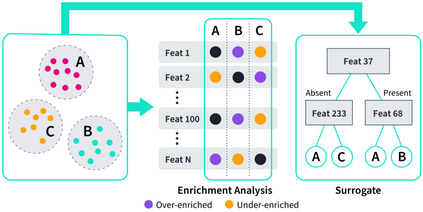
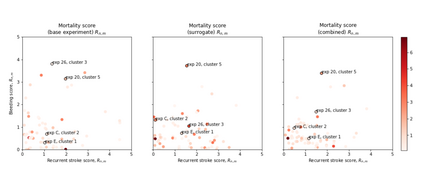
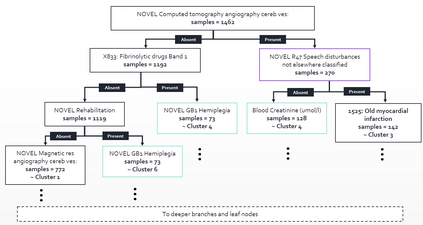
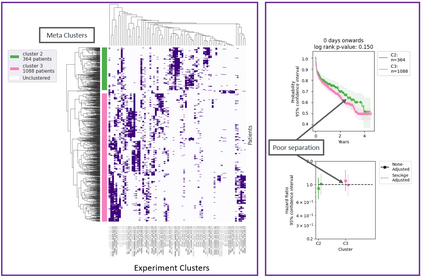
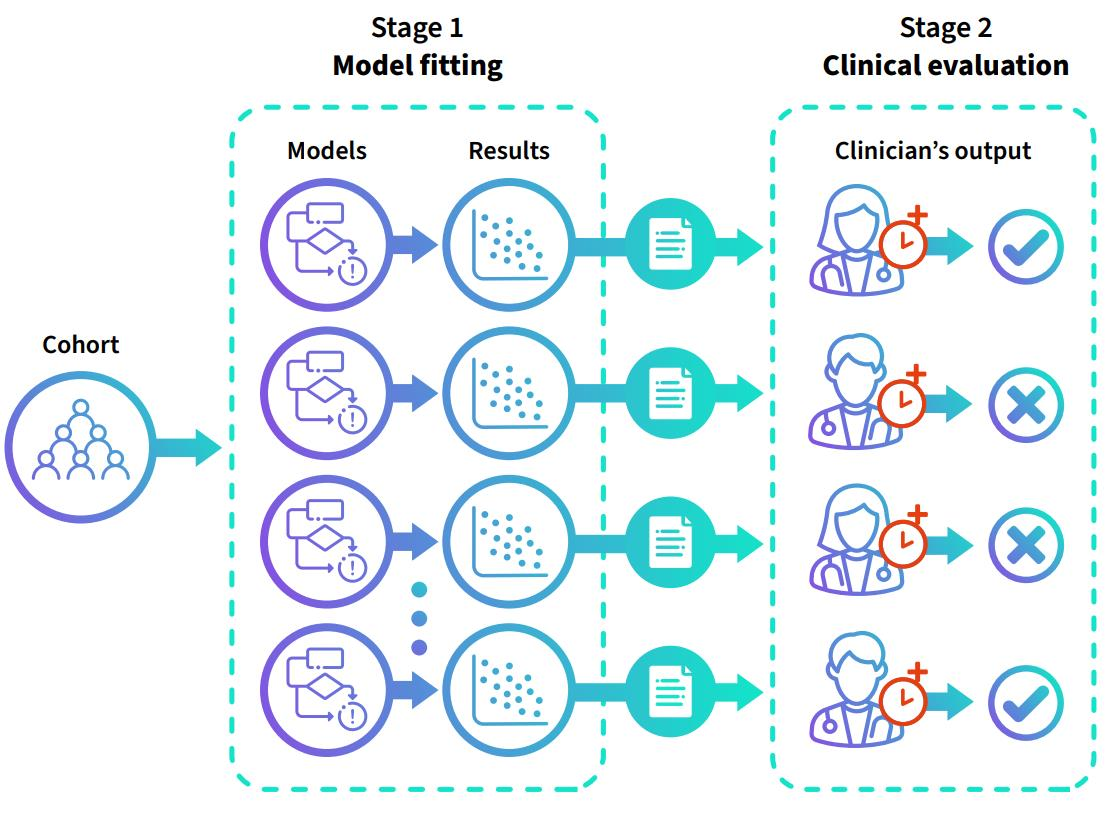
The availability of large and deep electronic healthcare records (EHR) datasets has the potential to enable a better understanding of real-world patient journeys, and to identify novel subgroups of patients. ML-based aggregation of EHR data is mostly tool-driven, i.e., building on available or newly developed methods. However, these methods, their input requirements, and, importantly, resulting output are frequently difficult to interpret, especially without in-depth data science or statistical training. This endangers the final step of analysis where an actionable and clinically meaningful interpretation is needed.This study investigates approaches to perform patient stratification analysis at scale using large EHR datasets and multiple clustering methods for clinical research. We have developed several tools to facilitate the clinical evaluation and interpretation of unsupervised patient stratification results, namely pattern screening, meta clustering, surrogate modeling, and curation. These tools can be used at different stages within the analysis. As compared to a standard analysis approach, we demonstrate the ability to condense results and optimize analysis time. In the case of meta clustering, we demonstrate that the number of patient clusters can be reduced from 72 to 3 in one example. In another stratification result, by using surrogate models, we could quickly identify that heart failure patients were stratified if blood sodium measurements were available. As this is a routine measurement performed for all patients with heart failure, this indicated a data bias. By using further cohort and feature curation, these patients and other irrelevant features could be removed to increase the clinical meaningfulness. These examples show the effectiveness of the proposed methods and we hope to encourage further research in this field.
翻译:大型和深层电子保健记录(EHR)数据集的可用性,有可能使人们更好地了解真实世界病人的历程,并查明新的病人分组。基于ML的EHR数据汇总大多是工具驱动的,即在现有或新开发的方法的基础上进行。然而,这些方法、其输入要求以及由此产生的产出往往难以解释,特别是在没有深入的数据科学或统计培训的情况下。这危及了分析的最后一步,即需要对病人进行可操作和临床上有意义的解释。本研究调查了使用大型EHR的临床数据集和临床研究的多重组群方法进行规模的病人分层分析的方法。我们开发了一些工具,以便利临床评估和解释未受监督的病人分层结果,即模式筛选、元集聚、代金建模和曲线。这些工具可以在分析的不同阶段使用。与标准分析方法相比,我们展示了浓缩结果和最佳分析时间。在元集方面,我们证明病人组群的数量可以迅速鼓励从72个到3个类集的临床数据测量结果。我们用这种血压测量方法演示了这个模型,另一个例子表明,我们用这种分层测量结果来测量结果。