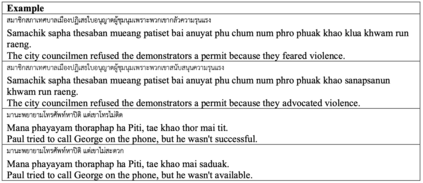
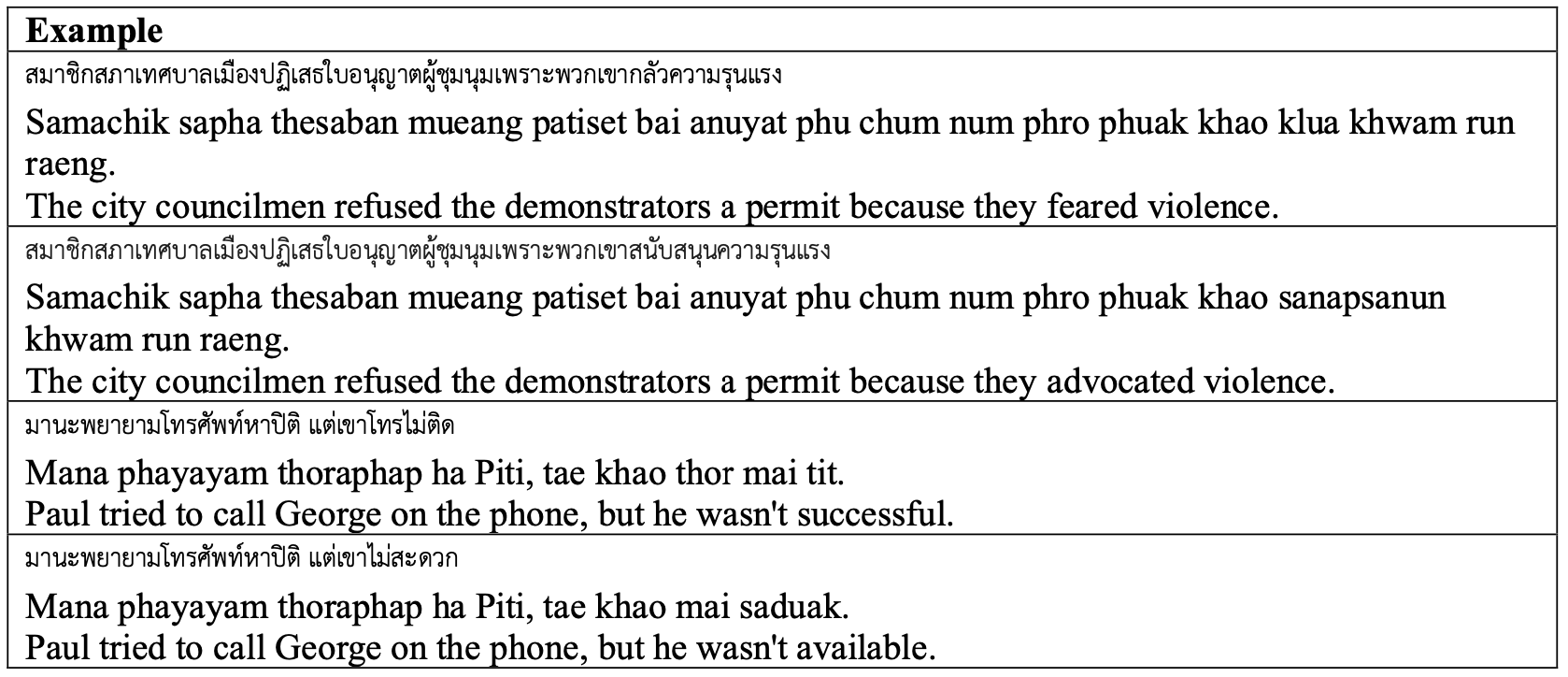
Commonsense reasoning is one of the important aspect of natural language understanding, with several benchmarks developed to evaluate it. However, only a few of these benchmarks are available in languages other than English. Developing parallel benchmarks facilitates cross-lingual evaluation, enabling a better understanding of different languages. This research introduces a collection of Winograd Schemas in Thai, a novel dataset designed to evaluate commonsense reasoning capabilities in the context of the Thai language. Through a methodology involving native speakers, professional translators, and thorough validation, the schemas aim to closely reflect Thai language nuances, idioms, and cultural references while maintaining ambiguity and commonsense challenges. We evaluate the performance of popular large language models on this benchmark, revealing their strengths, limitations, and providing insights into the current state-of-the-art. Results indicate that while models like GPT-4 and Claude-3-Opus achieve high accuracy in English, their performance significantly drops in Thai, highlighting the need for further advancements in multilingual commonsense reasoning.
翻译:暂无翻译