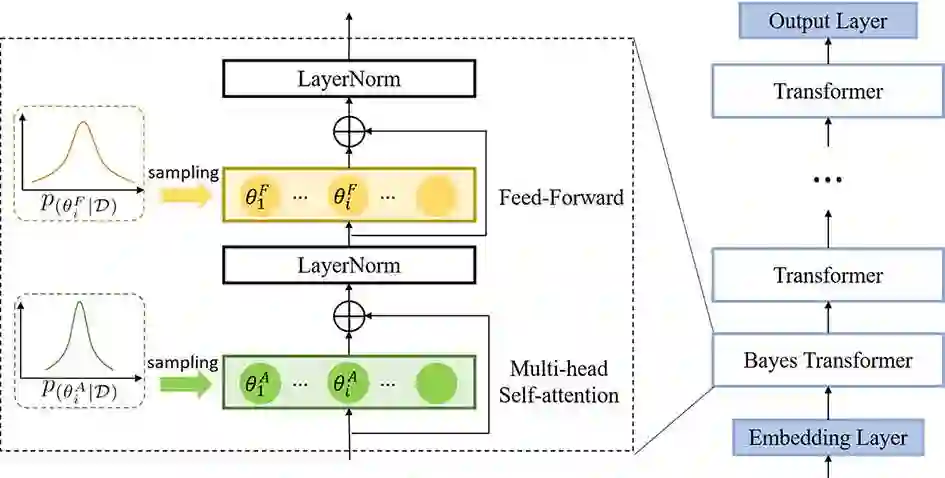
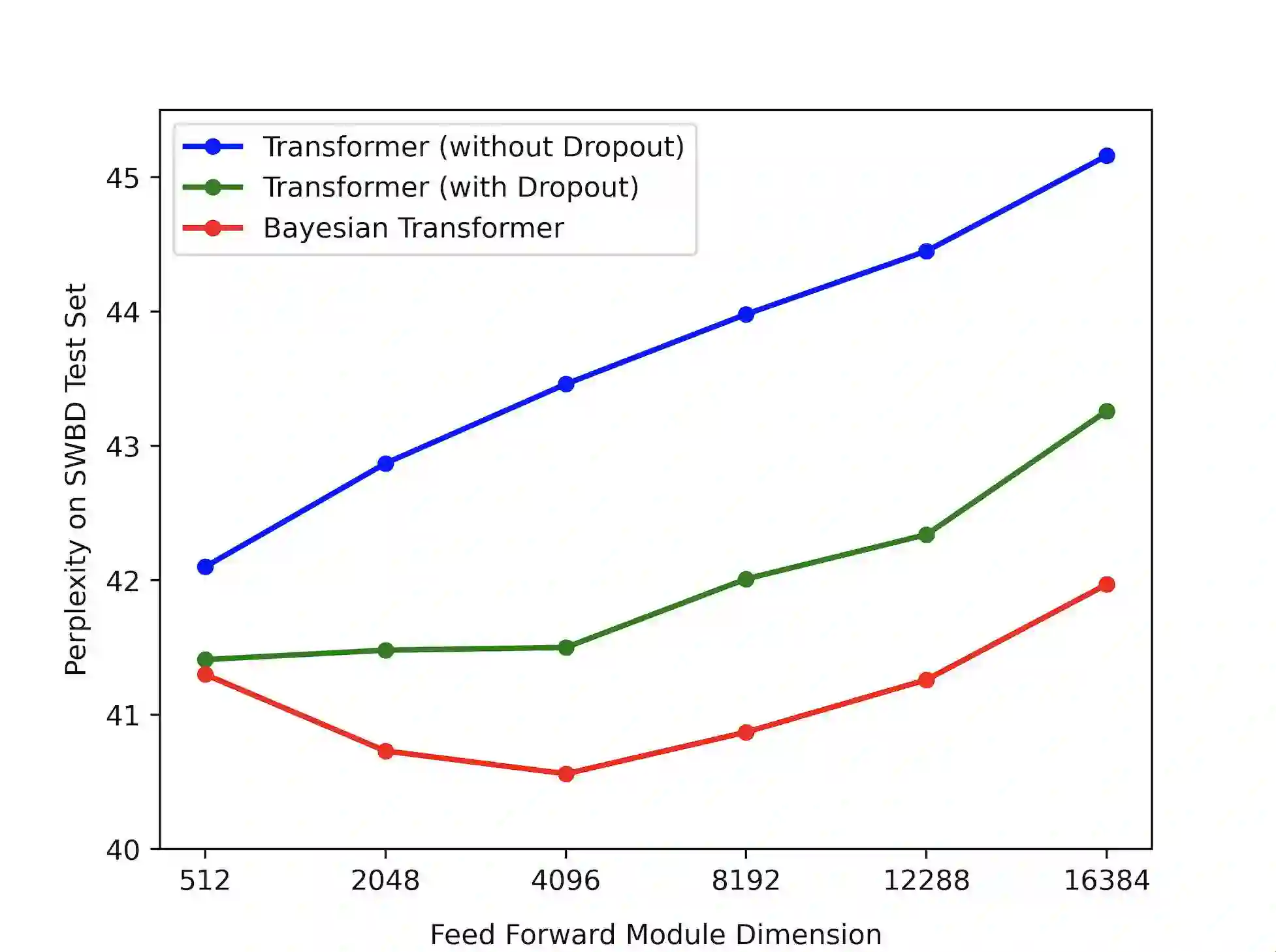
State-of-the-art neural language models (LMs) represented by Transformers are highly complex. Their use of fixed, deterministic parameter estimates fail to account for model uncertainty and lead to over-fitting and poor generalization when given limited training data. In order to address these issues, this paper proposes a full Bayesian learning framework for Transformer LM estimation. Efficient variational inference based approaches are used to estimate the latent parameter posterior distributions associated with different parts of the Transformer model architecture including multi-head self-attention, feed forward and embedding layers. Statistically significant word error rate (WER) reductions up to 0.5\% absolute (3.18\% relative) and consistent perplexity gains were obtained over the baseline Transformer LMs on state-of-the-art Switchboard corpus trained LF-MMI factored TDNN systems with i-Vector speaker adaptation. Performance improvements were also obtained on a cross domain LM adaptation task requiring porting a Transformer LM trained on the Switchboard and Fisher data to a low-resource DementiaBank elderly speech corpus.
翻译:为了解决这些问题,本文件建议为变异器LM估算一个完整的巴伊西亚学习框架。基于高效的变异推论的方法用于估计与变异器模型结构不同部分相关的潜在参数后部分布,包括多头自留、前进和嵌入层。在经过有限培训的FLM-MMI测算的FLM-MMI测算器基准变换器系统上,取得了显著的字差率(WER)降幅高达0.5 ⁇ 绝对值(3.18 ⁇ 相对值)和一致的两难性增益。在需要将开关机和渔业数据移植到低资源DementiaBank老年人语音系统的跨域LM适应任务上,也取得了绩效改进。