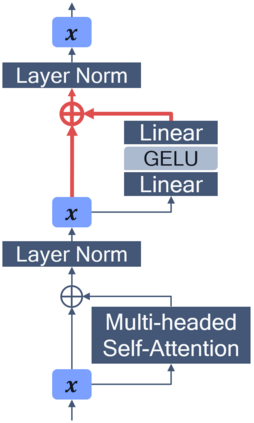
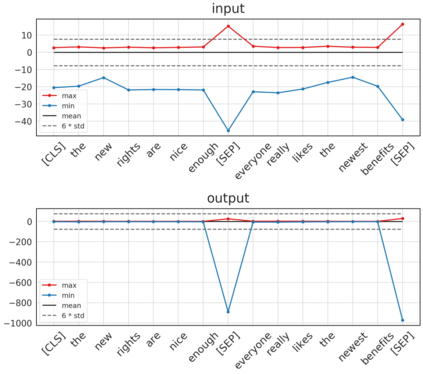
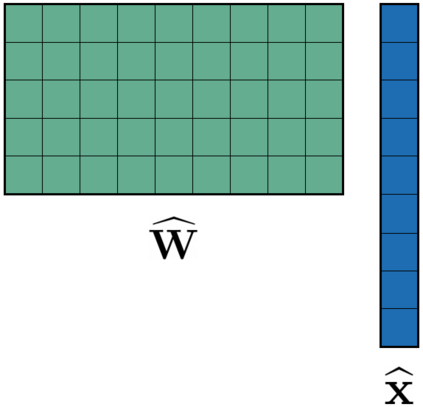
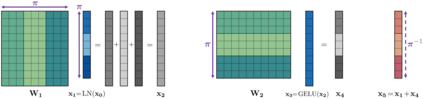
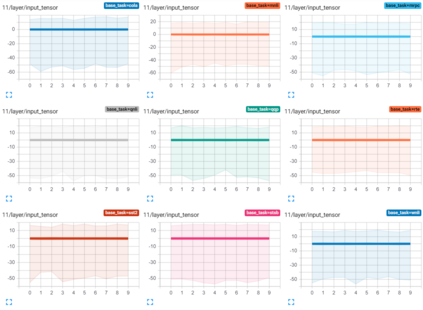
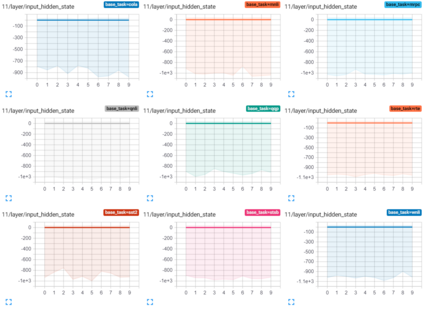
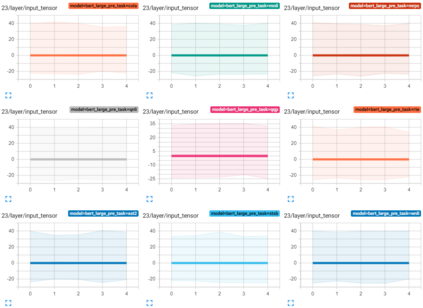
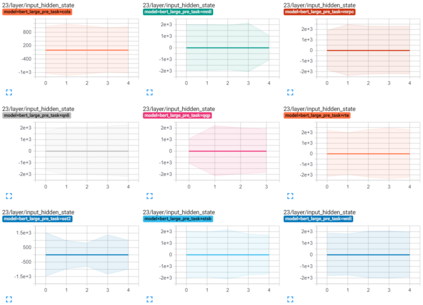
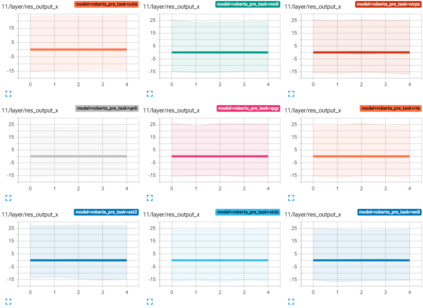
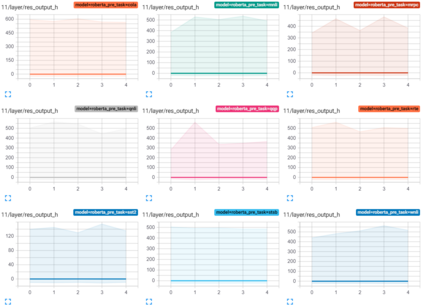
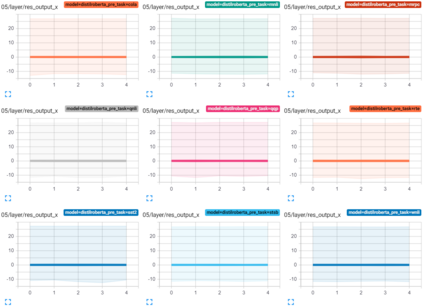
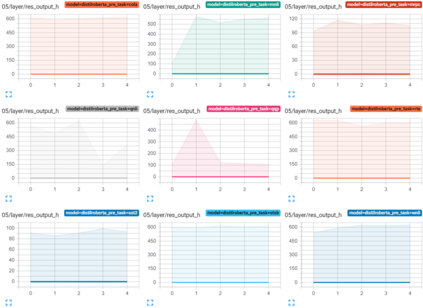
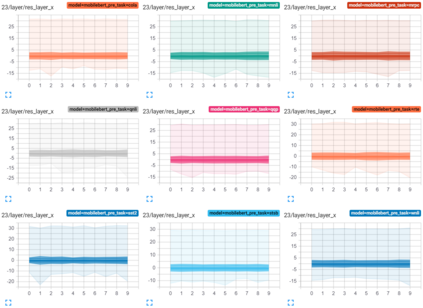
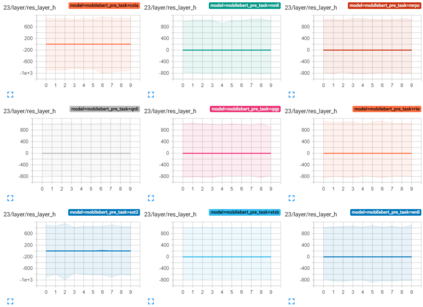
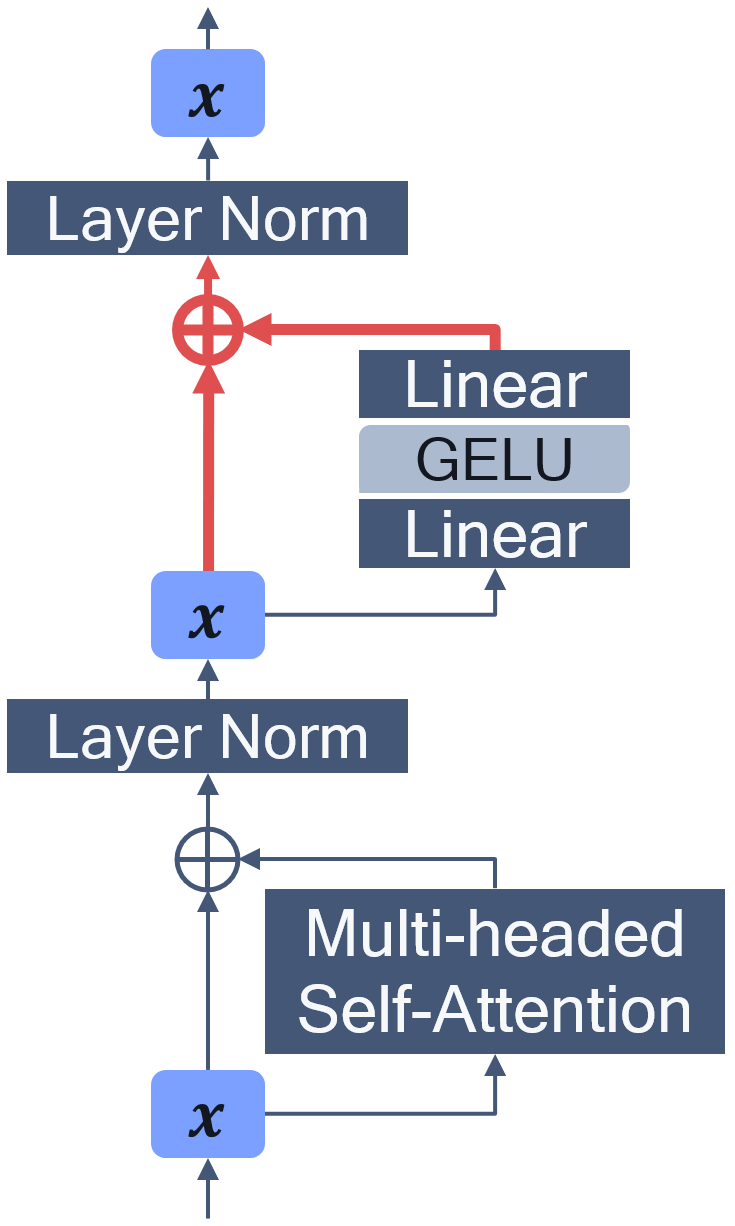
Transformer-based architectures have become the de-facto standard models for a wide range of Natural Language Processing tasks. However, their memory footprint and high latency are prohibitive for efficient deployment and inference on resource-limited devices. In this work, we explore quantization for transformers. We show that transformers have unique quantization challenges -- namely, high dynamic activation ranges that are difficult to represent with a low bit fixed-point format. We establish that these activations contain structured outliers in the residual connections that encourage specific attention patterns, such as attending to the special separator token. To combat these challenges, we present three solutions based on post-training quantization and quantization-aware training, each with a different set of compromises for accuracy, model size, and ease of use. In particular, we introduce a novel quantization scheme -- per-embedding-group quantization. We demonstrate the effectiveness of our methods on the GLUE benchmark using BERT, establishing state-of-the-art results for post-training quantization. Finally, we show that transformer weights and embeddings can be quantized to ultra-low bit-widths, leading to significant memory savings with a minimum accuracy loss. Our source code is available at~\url{https://github.com/qualcomm-ai-research/transformer-quantization}.
翻译:以变压器为基础的变压器结构已经成为一系列广泛的自然语言处理任务的脱facto标准模型。 但是,它们的记忆足迹和高悬浮度对于资源有限的设备的有效部署和推断来说是令人望而却步的。 在这项工作中,我们探索变压器的量化。 我们显示变压器有独特的量化挑战 -- -- 即难以以低位固定点格式代表的高动态激活范围。 我们确定这些激活装置包含鼓励特定关注模式的剩余连接结构外端,例如参加特殊分隔符。 为了应对这些挑战,我们提出了三种基于培训后量化和量化认知培训的解决方案,每种解决方案的精确度、模型大小和使用方便性都有不同的折衷办法。特别是,我们引入了一个新型的量化方案 -- -- 难于以低位固定点格式表示。 我们用BERT展示了我们GLUE基准方法的有效性,为培训后的量化设定了最先进的结果。 最后,我们展示了变压器重量和嵌入最小的精确度/正标值的存储系统可以进入极端的源。